카페에 가서 커피를 시킨 상황을 상상해보자. 고객들은 VIP, 일반 등급이 있다고 가정할 때. VIP는 빨리 서비스를 받아야 하고, 일반은 천천히 받는 그런 운영이다. 근데, VIP가 커피를 받기 전에 어떤 일반 고객이 바리스타에게 특별한 요청을 해서 VIP가 더 오래 기다리게 되었다고 상상해보자.
이 상황에서 VIP는 원래 높은 우선순위를 가지고 있었지만, 일반 고객 때문에 기다리게 된다. 이런 상황을 컴퓨터 운영체제에서도 볼 수 있다. 높은 우선순위를 가진 프로세스가 낮은 우선순위를 가진 프로세스 때문에 기다리게 되는 현상을 '우선순위 역전'이라고 한다.
< 발생원인 >
우선순위 역전은 주로 공유자원을 사용하는 상황에서 발생한다. 예를 들어, 낮은 우선순위 프로세스가 어떤 데이터를 사용 중인데, 높은 우선순위 프로세스도 그 데이터가 필요한 경우에 발생할 수 있다. 이 때, 높은 우선순위 프로세스는 낮은 우선순위 프로세스가 데이터를 놓을 때까지 기다려야 한다.
< 해결 방안 >
Priority Inheritance (우선순위 상속): 낮은 우선순위 프로세스가 높은 우선순위 프로세스 때문에 기다리게 되면, 낮은 우선순위 프로세스의 우선순위를 일시적으로 높여주면 된다.
예를 들자면 교실에서 숙제를 하는데, 1개의 계산기 밖에 없고, 내가 계산기가 필요한 상황이다. 그런데, 계산기는 친구가 사용 중이고, 친구는 우선순위가 낮다. 여기서 선생님이 들어오시면서 계산기를 빨리 사용하도록 친구에게 말하는 것처럼. 여기서 친구의 우선순위가 잠시 높아진 셈이다. 컴퓨터에서도 높은 우선순위의 프로세스가 기다리고 있다면, 낮은 우선순위 프로세스의 우선순위를 일시적으로 높여서 빨리 처리되도록 할 수 있다.
Priority Ceiling (우선순위 상한): 공유 자원에 접근하는 모든 프로세스의 우선순위를 미리 정해진 상한 값으로 설정하여, 높은 우선순위 프로세스가 대기하지 않도록 한다.
"단편화"란 컴퓨터 시스템의 저장소나 메모리에 데이터가 불연속적으로 위치하는 현상을 말한다. 이는 파일이 저장 공간의 여러 부분에 분산되어 저장되는 것을 의미하며, 이는 컴퓨터 성능을 저하시키는 주요 원인 중 하나이다. 따라서 파일이나 메모리 조각을 재조정하고, 파일을 연속된 공간에 저장하는 '디스크 조각 모음' 작업을 정기적으로 수행하는 것이 중요하다.
< 단편화의 원인과 영향 >
단편화는 파일이 저장 공간의 단일 연속 블록에 맞지 않거나, 파일을 저장하기에 충분한 자유 공간이 부족할 때 발생할 수 있다. 시스템이 파일을 열기 위해 개별 조각을 다른 위치에서 검색하고 가져와야 하기 때문에, 단편화는 파일을 읽거나 접근하는 데 문제를 일으킬 수 있다.
단편화의 결과로 시스템 성능이 감소하고 파일에 접근하기 어렵게 된다. 따라서 하드 디스크를 정기적으로 디스크 조각 모음하는 것이 좋다.
이 프로세스는 디스크의 데이터 블록을 재배열하여 파일이 연속된 블록에 저장되게 하고, 더 빠르게 접근할 수 있도록 한다.
< 단편화의 유형 >
[ 내부 단편화 ]
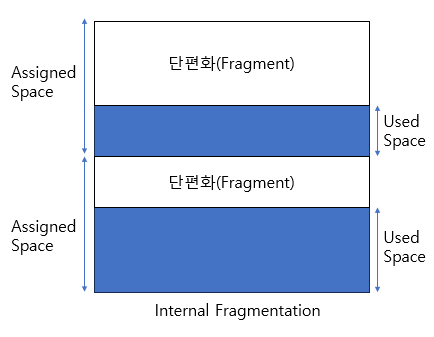
내부 단편화는 메모리 블록 내에 사용되지 않는 공간이 있을 때 발생한다. 예를 들어, 시스템이 40KB 크기의 파일을 저장하기 위해 64KB 메모리 블록을 할당하면, 그 블록에는 24KB의 내부 단편화가 포함된다. 고정 크기 블록 할당 방식을 사용하는 경우, 이러한 현상이 발생할 수 있다.
위의 다이어그램은 할당된 메모리와 필요한 공간 또는 메모리의 차이를 내부 단편화라고 부르기 때문에 내부 조각화를 명확하게 보여 준다 .
[ 외부 단편화 ]
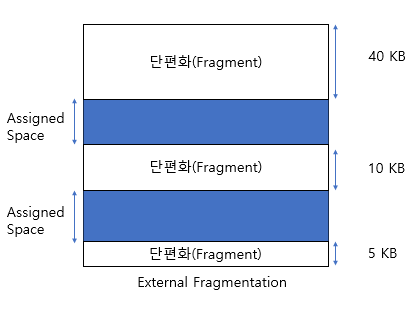
외부 단편화는 하드 디스크 같은 저장 매체가 여러 작은 자유 공간 블록을 산재시킬 때 발생한다. 시스템이 자주 파일을 생성하고 삭제하면 매체에 많은 작은 자유 공간 블록이 남아, 시스템이 새 파일을 저장할 때 충분히 큰 단일 연속 자유 공간 블록을 찾지 못하고, 대신 여러 작은 블록에 파일을 저장해야 할 수 있다. 이렇게 되면 외부 조각화와 성능 문제가 발생할 수 있다.
실행하기에 충분한 공간(55KB)이 있지만 Fragment가 연속적이지 않다는 것을 알 수 있다. 여기에서는 압축, 페이징 또는 분할을 사용하여 여유 공간을 사용하여 프로세스를 실행한다.
단편화는 시스템 내 다양한 수준에서 발생할 수 있다. 파일 단편화는 파일 시스템 수준에서 발생하며, 파일이 여러 비연속 블록으로 나뉘어 저장 매체에 저장된다. 메모리 단편화는 메모리 관리 수준에서 발생하며, 시스템이 동적으로 메모리 블록을 할당하고 해제한다. 네트워크 단편화는 네트워크를 통해 전송하기 위해 데이터 패킷이 작은 조각으로 나뉘어질 때 발생한다.
< 단편화가 운영체제에 미치는 영향 >
단편화는 디스크의 읽기 및 쓰기 속도를 느리게 만들어, 디스크 헤드가 파일의 조각에 접근하기 위해 여러 위치로 이동해야 한다. 때문에 접근 시간을 증가시키고 시스템의 전반적인 속도를 감소시킨다. 디스크 공간도 낭비되어, 조각이 필요한 공간보다 더 많은 공간을 차지할 수 있다. 이는 디스크 공간 부족을 초래하고, 시스템이 불안정해지며 오류나 충돌에 취약해질 수 있다. 심각한 경우에는 단편화로 인해 시스템이 디스크 공간을 모두 소진하여 데이터 손실을 일으킬 수 있다.
따라서 최적의 성능을 유지하기 위해서는 디스크를 정기적으로 조각 모음하는 것이 중요하다. 디스크 조각 모음은 파일의 조각을 재구성하고, 파일을 저장할 연속된 디스크 공간을 할당한다. 이는 디스크의 읽기 및 쓰기 속도를 향상시키고, 접근 시간을 줄이며, 시스템의 전반적인 속도를 향상시킨다. 디스크를 정기적으로 조각 모음함으로써 운영 체제의 성능을 향상시키고 유지할 수 있으며, 사용자에게 원활하고 효율적인 사용 환경을 제공할 수 있다.
< 단편화의 장점과 단점 >
단편화는 컴퓨터의 하드 디스크 또는 기타 저장 매체의 저장 공간을 더 잘 활용하는 등 여러 가지 잠재적인 이점이 있다. 단편화된 파일은 매체의 사용 가능한 자유 공간 블록에 저장할 수 있으며, 이러한 블록이 연속적일 필요는 없다. 이는 매체가 작은 자유 공간 블록을 많이 포함하고 있어 그렇지 않으면 낭비되는 경우 특히 유용하다.
그러나 일반적으로 단편화를 최소화하는 것이 좋다. 단편화는 시스템 성능에 부정적인 영향을 미치고, 파일의 접근 및 관리를 더 어렵게 만들 수 있다.
< 내부 단편화와 외부 단편화의 차이점 >
내부 단편화는 메모리가 고정 크기의 블록으로 분할되었을 때 발생한다. 과정이 메모리보다 작을 때 내부 단편화가 발생한다. 이 문제는 메모리 블록의 크기를 고정시킴으로써 발생한다. 동적 파티셔닝을 사용하여 프로세스에 공간을 할당하면 이 문제를 해결할 수 있다.
외부 단편화는 메모리에 충분한 양의 공간이 있지만 메모리가 비연속적인 방식으로 제공되어 프로세스의 메모리 요청을 충족시킬 수 없을 때 발생한다. 첫 번째 적합 또는 최선의 적합 메모리 할당 전략을 적용하면 외부 단편화가 발생한다. 단편화는 운영체제의 성능을 심각하게 저하시키는 주요 이슈이다.
디스크의 읽기 및 쓰기 속도를 느리게 만들어, 디스크 헤드가 파일의 조각에 접근하기 위해 다른 위치로 이동해야 하는 것이 단편화의 주요 역할이다. 이로 인해 접근 시간이 증가하고 시스템의 전반적인 속도가 감소하므로, 시스템 성능이 저하되고 애플리케이션에서 느려짐과 지연이 발생할 수 있다. 또한 단편화로 인해 디스크 공간이 낭비되고, 조각이 필요한 공간보다 더 많은 공간을 차지할 수 있다.이로 인해 디스크 공간 부족을 초래하고, 시스템이 불안정해지며 오류나 충돌에 취약해질 수 있다.
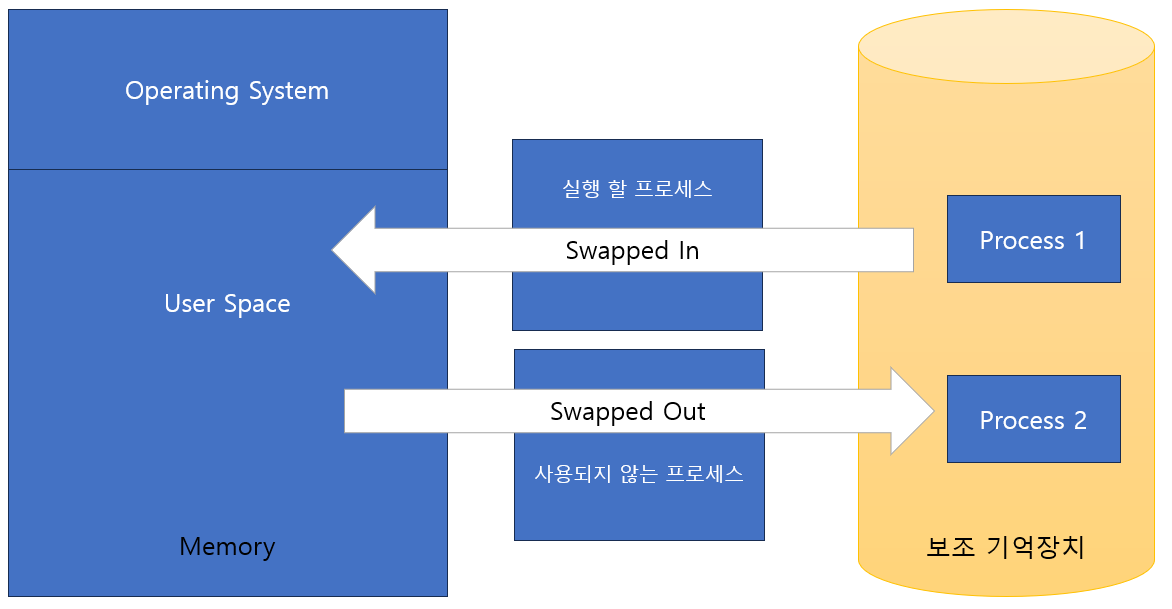
스왑핑이란, 주 메모리(RAM)에 올라와 있는 프로세스를 일시적으로 하드 디스크 같은 보조 메모리로 옮기는 과정을 말한다. 이렇게 하면 더 많은 프로세스를 동시에 실행할 수 있게 된다. 스왑핑은 '메모리 압축'이라고도 불리는데, 이는 하드 디스크를 메모리의 연장처럼 사용하여 메모리를 효율적으로 활용하기 때문이다.
스왑핑의 구체적인 과정을 살펴보면, 우선 CPU 스케줄러가 어떤 프로세스를 스왑아웃(swap-out)할지, 그리고 어떤 프로세스를 스왑인(swap-in)할지를 결정한다. 우선 순위가 높은 프로세스가 실행을 대기하고 있다면, 우선 순위가 낮은 프로세스를 스왑아웃하고, 높은 우선 순위의 프로세스를 메모리에 로드하여 실행한다. 이렇게 함으로써 CPU는 항상 가장 중요한 작업을 먼저 처리하게 된다.
< 스왑인과 스왑아웃 >
스왑핑은 크게 스왑인과 스왑아웃 두 가지 과정으로 나뉜다. 스왑아웃은 주 메모리에서 프로세스를 하드 디스크로 옮기는 것을 말하며, 반대로 스왑인은하드 디스크에서 프로세스를 다시 주 메모리로 가져오는 것을 말한다.
< 스왑핑의 장단점 >
[장점]
스왑핑을 통해 프로세스 실행 대기 시간을 줄일 수 있으며, 이는 결국 CPU의 활용도를 높이게 된다.
[단점]
프로세스가 주 메모리와 보조 메모리 간을 이동하는 과정은 시스템의 전체 성능을 떨어뜨릴 수 있다. 또한, 스왑핑 과정 중에 시스템이 갑자기 종료되면 스왑아웃된 프로세스의 데이터가 손실될 수 있다.
이 외에도, 스왑핑에 사용되는 알고리즘의 성능이 떨어질 경우 페이지 폴트의 발생 확률이 높아지며, 이는 전체 시스템 성능에 악영향을 미칠 수 있다.
그럼에도 불구하고, 메모리를 효율적으로 활용하기 위해 운영체제는 스왑핑과 같은 메모리 관리 기법을 사용하며, 이는 컴퓨터의 성능을 극대화하는데 중요한 역할을 한다.
< 메모리 할당 >
프로세스는 메모리 내의 빈 공간에 적재되어야 한다. 메모리 내에 빈 공간이 여러 개 있다면 프로세스를 어디에 배치해야 할까? 비어 있는 메모리 공간에 프로세스를 연속적으로 할당하는 방식을 알아보자.
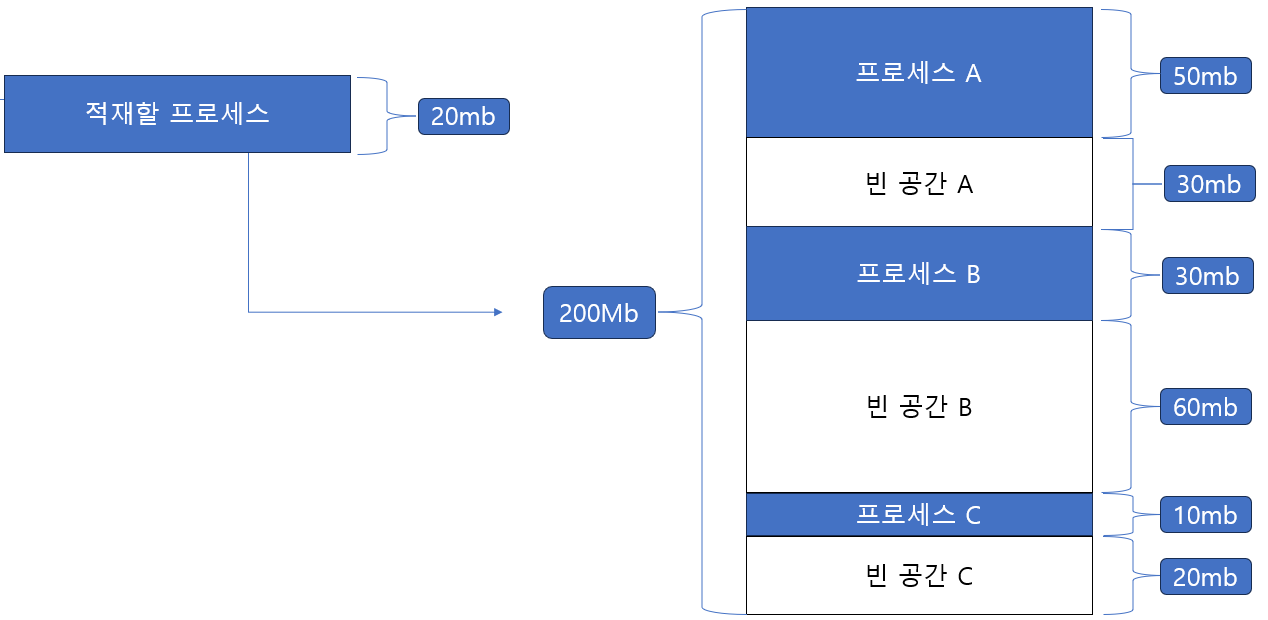
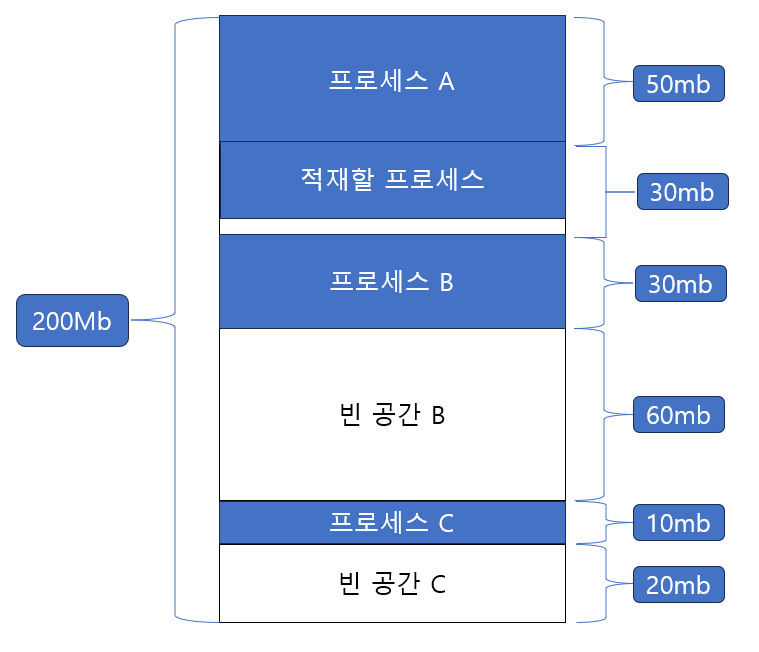
대표적으로 최초 적합, 최적 접합, 최악 적합의 세 가지 방식이 있다. 이는 그림과 함께 이해하는 것이 좋다. 가령 아래와 같은 상황에서 20MB 크기의 프로세스를 적재하고 싶다고 해보자. 메모리의 사용자 영역은 총 200MB라고 가정해 보자. 프로세스를 적재할 수 있는 빈 공간은 빈 공간 A, 빈 공간 B, 빈 공간 C 세군데가 있다.
[ 최초 적합 (first fit) ]
최초 적합 은 그 이름에서 알 수 있듯이, 운영체제가 메모리 내의 빈 공간을 순서대로 검색하다가 첫 번째로 발견한 적절한 공간에 프로세스를 배치하는 방식이다. 예를 들어, 운영체제가 A, B, C 순서로 메모리 공간을 검색하다가 프로세스가 적재될 수 있는 첫 번째 빈 공간 A를 발견하면, 해당 공간에 프로세스를 적재한다. 이 방식의 장점은 메모리 할당 속도가 빠르다는 것다. 적합한 공간을 발견하는 즉시 할당을 진행하므로, 불필요한 검색을 최소화할 수 있다.
최초 적합 방식은 최초로 발견한 적재 가능한 빈 공간에 프로세스를 배치하는 방식이다.
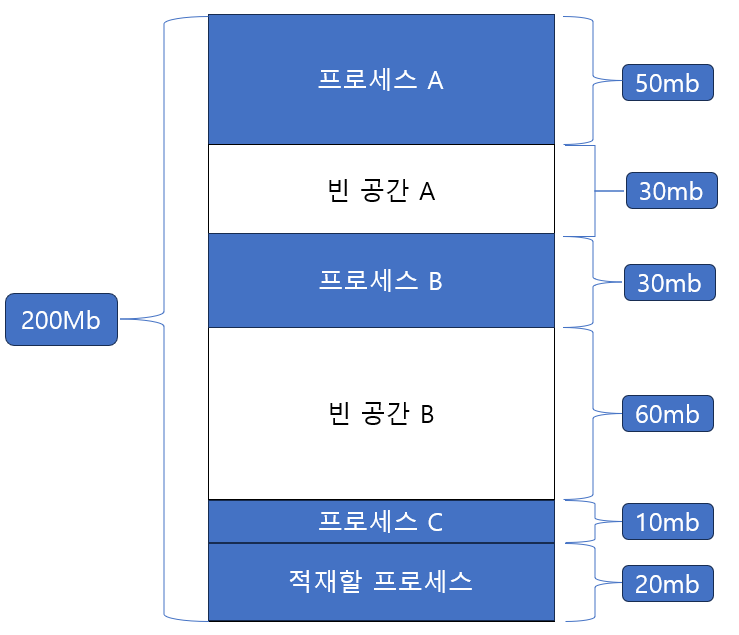
[ 최적 적합 (best fit) ]
최적 적합은 운영체제가 메모리의 모든 빈 공간을 검색한 후, 프로세스가 적재될 수 있는 공간 중에서 가장 작은 공간에 프로세스를 배치하는 방식이다. 예를 들어, 프로세스가 적합하게 적재될 수 있는 여러 빈 공간 중에서 가장 작은 공간이 C라고 하면, 운영체제는 프로세스를 C에 한다. 이 방식의 목표는 메모리 내의 남은 공간(내부 단편화)을 최소화하는 것이다.
최적 적합 방식은 프로세스가 적재될 수 있는 가장 작은 공간에 프로세스를 배치하는 방식
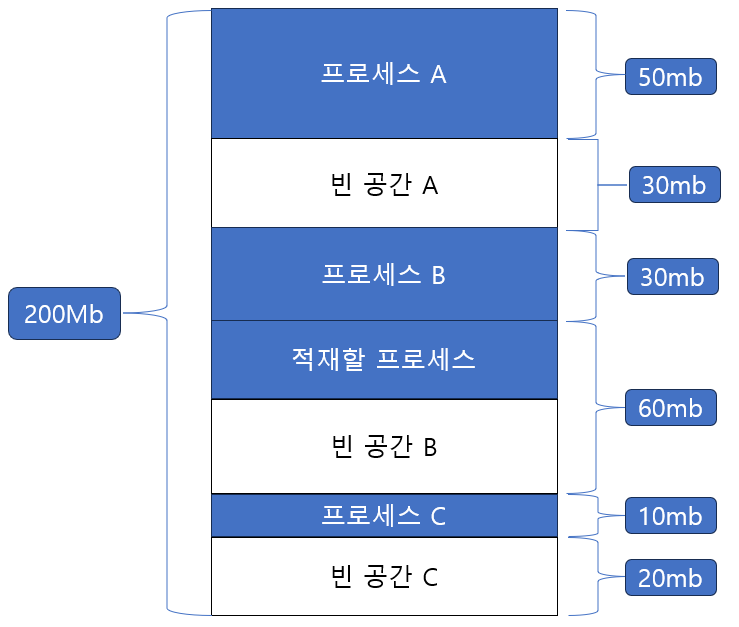
[ 최악 적합(worst fit) ]
최악 적합은 운영체제가 메모리의 모든 빈 공간을 검색한 후, 프로세스가 적재될 수 있는 공간 중에서 가장 큰 공간에 프로세스를 배치하는 방식이다. 위의 예시를 다시 사용하면, 프로세스가 적합하게 적재될 수 있는 여러 빈 공간 중에서 가장 큰 공간이 B라면, 운영체제는 프로세스를 B에 배치한다. 이 방식의 목표는 큰 프로세스의 요청을 처리할 수 있는 큰 메모리 블록을 가능한 유지하는 것이다.
최악 적합 방식은 프로세스가 적재될 수 있는 가장 큰 공간에 프로세스를 배치하는 방식이다.
컴퓨터가 메모리에 있는 명령어를 실행하려면 먼저 CPU가 메모리에서 해당 명령어를 가져와야 한다. 이런 과정을 '인출'이라고 부른다. 그러나 명령어를 CPU로 가져왔다 해도 바로 실행할 수 없는 경우도 있다. 예를 들어, 추가적으로 메모리에 접근해야 하는 경우가 있을 수 있다.
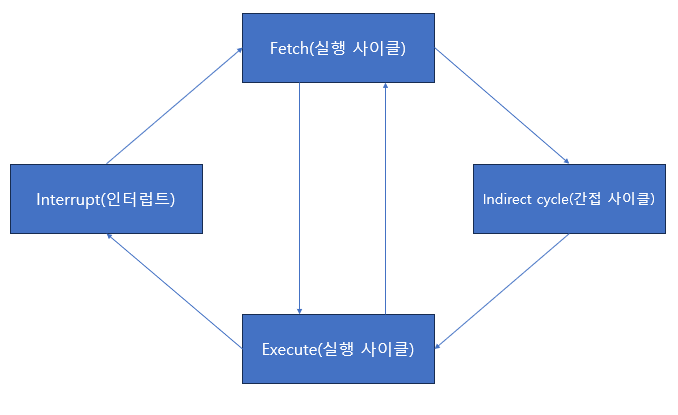
이런 과정들을 "명령어 사이클(instruction cycle)"이라고 한다.
명령어 사이클에는 크게 세 가지가 있다.
인출 사이클 (Fetch cycle): 메모리에서 명령어를 CPU로 가져오는 단계.
실행 사이클 (Execution cycle): CPU에서 명령어를 실행하는 단계. 여기서 제어 장치는 명령어 레지스터에 담긴 값을 해석하고 제어 신호를 발생시킨다.
간접 사이클 (Indirect cycle): 명령어를 실행하기 위해 한 번 더 메모리 접근을 하는 과정을 간접 사이클이라고 한다. 간접 주소 지정 방식을 사용하는 경우에 필요한 사이클이다.
( 인터럽트: CPU에게 긴급한 일을 알리는 방법 )
명령어 사이클이 원활하게 진행되는 동안, 때때로 CPU는 '인터럽트'라는 메시지를 받는다. 이 메시지는 "CPU야, 지금 다른 일을 하고 있더라도 이건 긴급해서 지금 당장 처리해야 하는 일이야"라는 식의 메시지이다.
인터럽트는 크게 두 가지로 나뉜다.
< 동기 인터럽트 (예외) >
CPU가 예기치 못한 상황에 부딪혔을 때 발생한다. 예를 들면, CPU가 접근해야 하는 주소에 접근했는데 메모리가 없거나, 연산 중 오버플로우가 발생하는 경우가 있다. 이런 경우, CPU는 현재의 작업을 중단하고 이러한 예외 상황을 처리한다.
< 비동기 인터럽트 >
인터럽트는 CPU가 다른 작업을 수행하는 도중에 외부에서 발생하는 이벤트에 의해 발생한다. 이들은 주로 입출력 장치(IO devices), 타이머, 그리고 다른 프로세서에서 발생한다. 예를 들어, 키보드가 키 입력을 받았거나, 네트워크 카드가 데이터 패킷을 받았을 때 이런 비동기 인터럽트가 발생할 수 있다. 이러한 인터럽트가 발생하면 CPU는 현재의 작업을 일시 중단하고 이 인터럽트를 처리한다.
인터럽트가 발생하면 CPU는 현재 실행 중인 명령어를 완료한 후 인터럽트 처리를 시작한다. 이는 인터럽트가 발생한 시점의 CPU 상태를 저장하고, 해당 인터럽트를 처리하는 데 필요한 서비스 루틴으로 점프하는 과정을 포함한다. 인터럽트 처리가 완료되면, CPU는 인터럽트가 발생하기 전의 상태를 복구하고, 원래의 작업을 계속 수행한다.
정리하자면, CPU가 메모리에 저장된 명령어를 처리하는 과정은 명령어 사이클을 통해 이루어지며, 때때로 긴급한 작업을 처리해야 할 때는 인터럽트가 발생한다. 이렇게 명령어 사이클과 인터럽트를 통해 CPU는 다양한 작업을 효율적으로 처리하며, 컴퓨터 시스템이 원활하게 작동하도록 돕는다.
연산과 프로그램의 실행을 효율적으로 수행하기 위해 사용되며, 이를 위해 컴퓨터 메모리와 상호 작용하는 여러 가지 레지스터가 있다.
레지스터의 핵심 목적은 데이터를 빠르게 CPU로 가져오는 것이다. RAM에서 명령어를 가져오는 것은 하드 드라이브보다 빠르지만, CPU에게는 못 미친다.(속도 : RAM < CPU)
※ 레지스터는 메모리의 일종이지만, 흔히 이야기하는 RAM과는 다르다.
RAM이라는 용어는 주로 CPU 외부에 위치한 주 메모리를 가리킨다. 반면, 레지스터는 CPU 내부에 위치하며, 아주 빠른 속도로 데이터에 액세스할 수 있는 작은 메모리 장치( 레지스터는 매우 작은 용량을 가졌기에, 이런 작은 용량 덕분에 레지스터는 매우 빠른 속도로 데이터에 액세스하고 처리할 수 있다.)다.
레지스터는 작고, 빠르기에 CPU가 연산을 수행하는 데 필요한 중요한 정보(예: 명령어, 데이터, 주소 등)를 임시 저장한다.
< 레지스터의 종류와 기능 >
Accumulator : 데이터를 메모리에서 가져와 저장하는 데 가장 자주 사용되는 레지스터이다.
Memory Address Registers (MAR): 메모리의 접근할 위치의 주소를 가지고 있는 레지스터.
MAR와 MDR(Memory Data Register)이 함께 작동하여 CPU와 주 메모리 간의 통신을 지원한다.
Memory Data Registers (MDR) : 주소 지정된 위치에서 읽어야 할 데이터 또는 기록해야 하는 데이터를 포함한다.
General Purpose Registers : 임시 데이터를 저장하는 데 사용되며, 어셈블리 프로그래밍에서 그 내용에 액세스 할 수 있다. 현대의 CPU 아키텍처는 레지스터 대 레지스터 주소 지정을 더 많이 사용할 수 있도록 더 많은 일반 목적 레지스터를 사용하는 경향이 있다.
Program Counter (PC) : 프로그램의 실행을 추적하는 데 사용된. 이는 다음에 가져올 명령어의 메모리 주소를 포함한다.
Instruction Register (IR): 바로 실행될 명령어를 가지고 있다. PC에서 가져온 명령어가 IR에 저장되며, IR에 명령어가 위치하자마자 CPU는 명령어를 실행하기 시작하고 PC는 다음에 실행될 명령어를 가리킨다.
< 레지스터의 장점과 단점 >
레지스터는 매우 빠르며, 메인 메모리보다 훨씬 빠르게 데이터에 액세스할액세스 할 수 있다. 또한, 효율적으로 작은 양의 데이터만 저장하도록 설계되었으며, 이는 CPU가 쉽게 액세스 할 수 있게 한다.
그러나 레지스터에는 일부 단점도 있다. 레지스터는 소량의 데이터만 저장할 수 있어 일부 애플리케이션에서 문제가 발생할 수 있으며, 높은 속도의 메모리 셀로 만들어져 있어 CPU의 비용이 증가한다.
컴퓨터 시스템에서 프로세스(일련의 명령어로 구성된 작업)를 실행하려면 여러 가지 리소스(메모리, CPU 시간, 디스크 공간 등)가 필요하다. 시스템은 이러한 리소스를 프로세스에 순차적으로 할당하며, 프로세스가 작업을 완료하면 사용한 리소스는 시스템에 다시 반납된다.
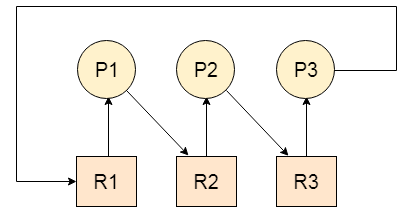
그러나 여러 프로세스가 동시에 실행되는 시스템에서는 복잡한 상황이 발생할 수 있다. 이를 이해하기 위해 간단한 예시로, 세 가지 프로세스 P1, P2, P3와 세 가지 리소스 R1, R2, R3이 있다고 가정해보자. 이 시점에서 각각의 프로세스는 이미 하나의 리소스를 할당 받았다고 가정하자: P1은 R1, P2는 R2, P3는 R3을 갖고 있다고 가정.
그런데 이후에 추가적인 리소스를 필요로 하는 상황이 발생하였다. P1이 R2를 필요로 하고, P2가 R3를 필요로 하며, 마지막으로 P3는 R1을 필요로 하게되었다.
문제는 이제 각 프로세스가 필요로 하는 리소스가 이미 다른 프로세스에게 할당되어 있어서 사용할 수 없는 상황이다. 따라서, 모든 프로세스들은 각자 필요한 리소스가 반납될 때까지 대기 상태에 빠지게 되며, 이는 데드락이라는 현상으로 이어져버린다. 데드락은 프로세스들이 더 이상 진행할 수 없는 상태로, 시스템 성능에 심각한 영향을 미치게 된다.
교착 상태를 표현한 상황, P1 프로세스는 R2자원이 끝나길 기다리고 있고, P2 프로세스는 자원 R2를 할당 받은 채 R3의 자원이 끝나길 기다리는 상황
< 데드락 발생 조건 >
데드락이 발생하려면 아래와 같은 네 가지 조건이 만족되어야 한다.
Mutual Exclusion (상호 배제) : 리소스는 한 번에 한 프로세스만 사용할 수 있다. Hold and Wait (점유와 대기) : 프로세스는 이미 할당된 리소스를 가진 상태에서 다른 리소스를 기다린다. No Preemption (비선점) : 한 프로세스가 이미 점유하고 있는 리소스를 다른 프로세스가 강제로 빼앗을 수 없다. Circular Wait (원형 대기) : 프로세스 A, B, C가 있을 때 A는 B가 가진 리소스를, B는 C가 가진 리소스를, C는 A가 가진 리소스를 기다리는 상황을 말한다.
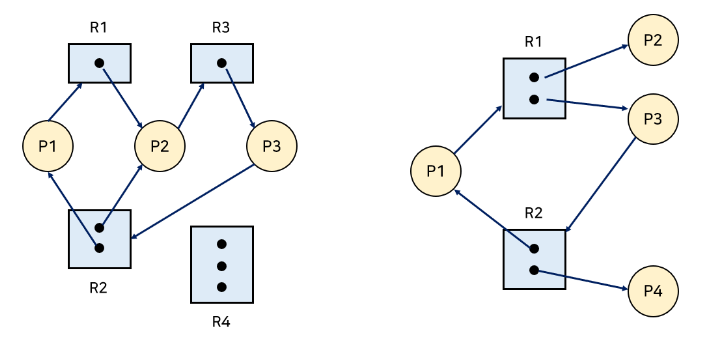
프로세스 간의 관계를 그래프로 도식화해 보면 데드락이 발생할지 예상할 수 있다. 이 그래프를 Resource-Allocation Graph(자원 할당 그래프)라고 한다. 예시를 하나 살펴보자.
R은 자원이고 P는 프로세스를 의미한다. 자원 내의 동그라미는 자원(인스턴스)의 개수이다.
자원 → 프로세스로 향하는 간선은 해당 자원을 프로세스가 보유 중(Allocate)이라는 의미이고, 프로세스 → 자원으로 향하는 간선은 프로세스가 해당 자원을 요청(Request)했다는 의미이다.
만약 그래프에 사이클(Cycle)이 없다면 Deadlock이 아니다. 반면, 사이클이 있다면 Deadlock이 발생할 '수' 있다.
정확히 말하면, 자원당 하나의 인스턴스만 있는 경우엔 Deadlock이고, 여러 인스턴스가 존재하는 경우엔 Deadlock일 수도 있고 아닐 수도 있다. 위의 그림에서는 왼쪽 그래프는 Deadlock이지만, 오른쪽 그래프는 Deadlock이 아니다.
Deadlock문제를 해결하기 위한 방법으로는 대표적으로 미리 예방하는 방법(Prevention)과 Deadlock이 발생하지 않도록 피하는 방법(Avoidance), 그리고 발생했을 때 처리하는 방법(Detection and Recovery), 무시하는 방법(Ignorance) 총 네 방법으로 나뉜다.
이 네 가지 조건 중에서 하나라도 만족되지 않으면 데드락은 발생하지 않는다.
< 데드락 해결 방법 >
그렇다면 이러한 데드락을 어떻게 해결할 수 있을까? 데드락을 처리하는 방법에는 크게 세 가지가 있다.
1.데드락 예방, 2. 데드락 회피,3. 데드락 복구가 있다.
[데드락 예방] 데드락 예방은 데드락 발생 조건 중 하나를 만족시키지 않도록 하여 데드락이 발생하지 않도록 하는 방법이다. 하지만 이 방법은 장치 효율과 시스템 성능을 떨어트릴 수 있다.
[데드락 회피] 데드락 회피는 데드락이 발생할 것 같을 때는 아예 리소스를 할당하지 않는 방법이다. 이 방법은 시스템 상태를 항상 안전한 상태로 유지하는 것이 중요하며, 리소스 할당 그래프를 통해 데드락 가능성을 판단한다. 만약 리소스 타입이 여러 개라면 은행원 알고리즘(Banker's Algorithm)을 사용한다.
[데드락 복구] 데드락 복구는 데드락이 발생한 후에 어떤 프로세스를 중단시킬지 결정하는 것이. 여기에는 프로세스의 중요도, 실행 시간, 사용 리소스 양, 필요 리소스 양 등 다양한 판단 기준이 있다.
[리소스 선점] 데드락을 해결하기 위해 리소스 선점 방식을 사용할 수도 있다. 하지만 이 경우 어떤 프로세스를 중단시킬지 결정하는 것이 중요하며, 데드락 발생 전 상태로 되돌리는 rollback 과정이 필요하다. 그리고 계속 같은 프로세스가 중단되는 starvation 문제를 피해야 한다.
프로세스의 동기화는 어떻게 이루어질까? 어떻게 해야 임계 구역에 오직 하나의 프로세스만 진입하게 하고, 올바른 실행 순서를 보장할 수 있을까? 이를 위해 동기화를 위한 대표적인 도구인 뮤텍스 락, 세마포,모니터가 있다.
< 뮤텍스 락 (Mutex Lock) >
뮤텍스 락은 프로세스의 동기화를 위한 가장 기본적인 도구이다. Mutex란 'Mutual Exclusion'의 약자로, 한 번에 하나의 프로세스만 공유 자원에 접근할 수 있게 하는 기법을 말한다. 이는 동시에 실행되는 여러 프로세스 또는 스레드가 동일한 자원을 동시에 사용하려 할 때 발생하는 경쟁 조건을 방지하는데 사용된다.
Java에서는 'synchronized' 키워드를 사용해 뮤텍스 락을 구현할 수 있고, Lock 인터페이스를 이용하는 방법이 있다.
synchronized 키워드 : 이 키워드를 메서드 또는 블록 앞에 사용하면 해당 메서드는 블록에 동시에 하나의 스레드만 접근할 수 있다. 'synchronized' 키워드는 내부적으로 락을 관리하므로 사용자가 락을 명시적으로 획득하거나 해제하는 코드를 작성할 필요가 없다. 그러나 'synchronized' 키워드를 사용할 때는 잘못된 사용으로 인해 교착 상태(deadlock)이 발생할 가능성을 주의해야 한다.
[synchronized 키워드를 이용한 뮤텍스 락 구현 코드 1]
class SharedResource {
synchronized void accessResource() {
// 임계 영역
}
}
[synchronized 키워드를 이용한 뮤텍스 락 구현 코드 2]
class SharedResource {
synchronized void access(String threadName) {
System.out.println(threadName + " is accessing shared resource");
// 작동하는 코드 여기 넣기
System.out.println(threadName + " is leaving shared resource");
}
}
이 코드에서 synchronized 키워드는 한 번에 한 스레드만 'access'메서드를 실행할 수 있게 해준다. 이런 방식은 "영화관에서 한 번에 하나의 티켓만 팔 수 있다"는 개념과 유사하다.
Lock 인터페이스 (ReentrantLock 클래스):
java.util.concurrent.locks 패키지에 있는 Lock 인터페이스와 그 구현체인 ReentrantLock 클래스를 사용하면 뮤텍스 락을 구현할 수 있다. 이 방법을 사용하면, 락의 획득과 해제를 명시적으로 제어할 수 있다. 또한, 'tryLock'메서드를 사용해 락을 시도적으로 획득할 수 있는 옵션이 있어 데드락을 피하는 데 도움이 될 수 있다.
[ReentrantLock 클래스를 구현해서 만든 뮤텍스 락]
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class SharedResource {
private Lock lock = new ReentrantLock();
void accessResource() {
lock.lock();
try {
// 임계 영역
} finally {
lock.unlock();
}
}
}
< 세마포어 (Semaphore) >
세마포어는 뮤텍스 락과 비슷하게 공유 자원에 대한 접근을 제어한다. 그러나 세마포어는 한 번에 여러 개의 동일한 자원을 사용할 수 있는 프로세스나 스레드의 수를 제한할 수 있다. "한 번에 n 개의 티켓을 팔 수 있는 영화관"과 유사한 개념이다.
모니터는 뮤텍스 락과 세마포어를 확장한 개념이다. 모니터는 공유 자원에 대한 접근을 제어하는 동시에, 특정 조건을 만족할 때까지 프로세스나 스레드를 대기 상태로 만든다. 이것은 "영화가 시작할 때까지 대기실에서 기다리는 고객"과 유사한 개념이다.
C#에서는 Monitor 클래스를 사용해 모니터를 구현할 수 있다.
using System;
using System.Threading;
class SharedResource {
private static readonly object _lock = new object();
public void Access(string threadName) {
Monitor.Enter(_lock);
try {
Console.WriteLine($"{threadName} is accessing shared resource");
// do some work here
Console.WriteLine($"{threadName} is leaving shared resource");
} finally {
Monitor.Exit(_lock);
}
}
}
컴퓨터 환경에서 여러 프로세스가 동시에 실행될 때, 공동의 목적을 올바르게 수행하기 위해 서로 협력하고 영향을 주고 받는다. 예를 들어, 워드 프로세서에서는 사용자 입력을 받는 프로세스,입력된 내용의 맞춤법을 검사하는 프로세스, 그리고 그 내용을 화면에 출력하는 프로세스가 있다. 이러한 프로세스들은 각기 독립적이지만 공동의 목적을 위해 서로 협력한다.
이렇게 협력하여 실행되는 프로세스들을 올바르게 관리하기 위해 프로세스 동기화가 필요하다.
< 프로세스 동기화란? >
프로세스 동기화는 한마디로 말하자면, 여러 프로세스 사이의 실행 순서를 조정하는 것이다. 이를 통해 다음과 같은 두 가지 중요한 기능을 수행한다.
실행 순서 제어 : 프로세스를 올바른 "순서대로" 실행하기
상호 배제 : 동시에 접근해서는 안되는 자원에 하나의 프로세스만 접근하게 하기
※ 스레드 등 실행의 흐름을 갖는 모든 것도 동기화에 대상이며, 이를 통해 특정 자원에 한 개의 프로세스만 접근하게 하거나, 프로세스를 올바른 순서대로 실행하는 것을 보장한다.
< 동기화 예시 >
실행 순서 제어 예시: "Writer" 프로세스와 "Reader" 프로세스가 동시에 실행되고 있다고 가정해 보자. Writer 프로세스는 파일에 값을 쓰는 역할을 하고, Reader 프로세스는 해당 파일에서 값을 읽어 들이는 역할을 한다. 이 경우, Reader 프로세스가 Writer 프로세스가 파일에 값을 쓴 이후에야 실행될 수 있어야 한다. 이렇게 실행 순서를 제어하는 것이 프로세스 동기화의 첫 번째 요소이다.
상호 배제 예시: 두 프로세스가 동시에 한 계좌에 입금을 하는 상황을 생각해 보자. 프로세스 A는 2만 원을 입금하고, 프로세스 B는 5만 원을 입금한다. 이 두 프로세스가 동시에 계좌에 접근하면 잔액이 올바르게 갱신되지 않을 수 있다.이런 상황을 방지하기 위해 한 번에 하나의 프로세스만 계좌에 접근할 수 있도록 하는 것이 상호 배제이다.이것이 프로세스 동기화의 두 번째 요소이다.
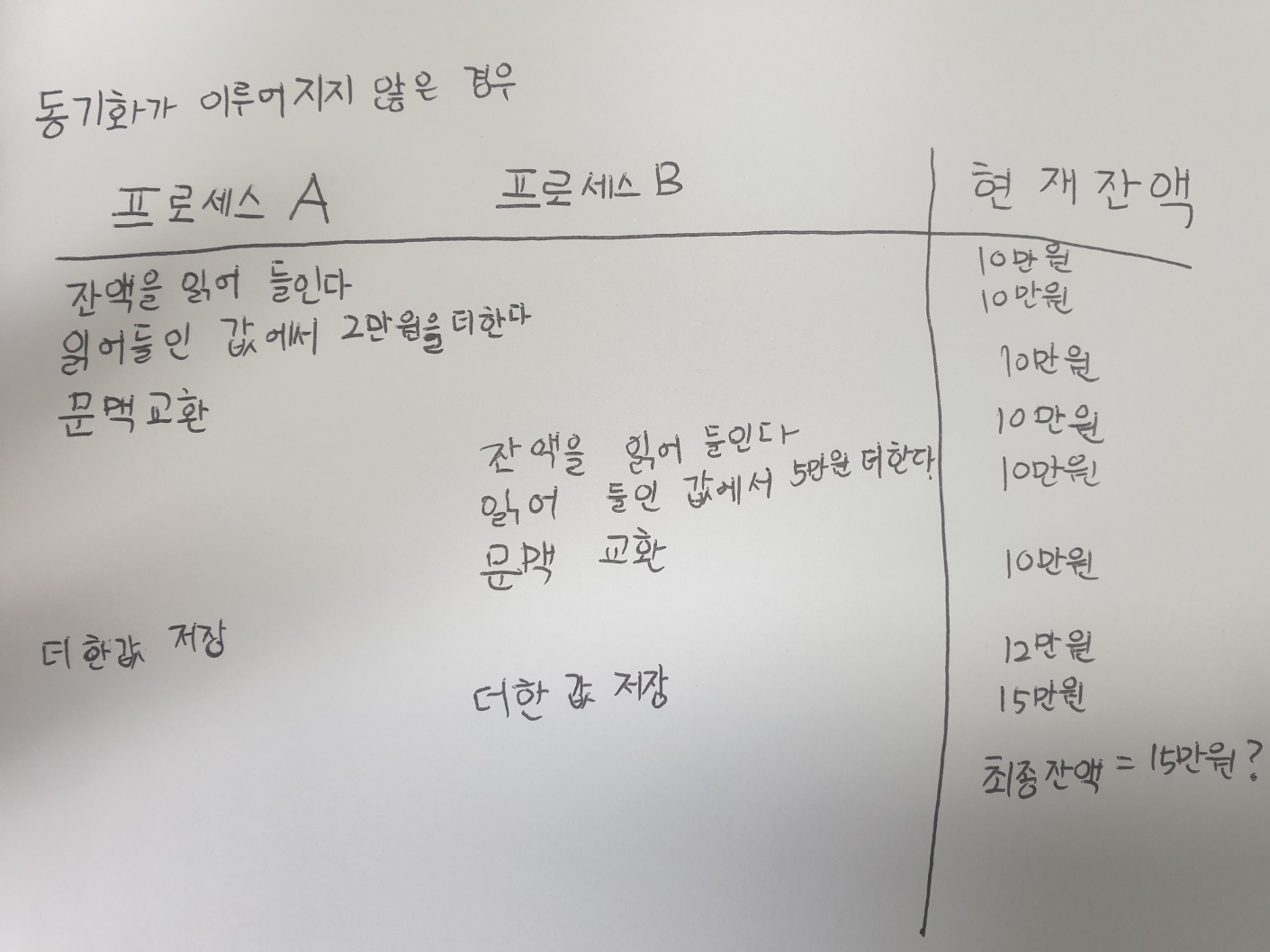
프로세스 A가 실행되는 과정을 조금 더 자세히 표현해 보면 아래와 같이 나타낼 수 있다.
①계좌에 잔액을 읽어 들인다.
②읽어 들인 잔액에 2만 원을 더한다.
③더한 값을 저장한다.
마찬가지로 프로세스 B가 실행되는 과정은 아래와 같은 순서로 나타낼 수 있다.
①계좌의 잔액을 읽어 들인다.
②읽어 들인 잔액에 5만 원을 더한다.
③더한 값을 저장한다.
이제 프로세스 A와 B와 동시에 실행되었다고 가정해 보자. 당연히 실행 결과 17만 원이 계좌에 남을 것을 기대할 것이다. 하지만 동기화가 제대로 이루어지지 않은 경우 아래와 같이 전혀 엉뚱한 결과가 나올 수 있다.
왜 이런 일이 발생했을까? A와 B는 '잔액'이라는 데이터를 동시에 사용하는데, A가 끝나기도 전에 B가 잔액을 읽어 버렸기 때문에 엉둥한 결과가 나온 것이다. A와 B를 올바르게 실행하기 위해서는 한 프로세스가 잔액에 접근했을 때 다른 프로세스는 기다려야 한다. 아래와 같이 말이다.
이렇게 동시에 접근해서는 안 되는 자원에 동시에 접근하지 못하게 하는 것이 상호 배제를 위한 동기화 이다.
동시에 실행되는 프로세스나 스레드는 종종 공유 자원에 대한 접근이 필요하다. 이 공유 자원은 메모리,파일,데이터베이스 연결 등 다양한 형태를 가질 수 있다. 이런 공유 자원에 대한 접근이 잘못 관리되면 데이터 불일치와 같은 문제가 발생할 수 있다. 그래서 이를 방지하기 위해 프로세스 동기화를 통해 공유 자원에 대해 접근을 제어한다.
< 공유 자원과 임계 구역 >
공유 자원은 여러 프로세스나 스레드가 동시에 접근하려고 하는 자원이다. 이런 자원에 동시에 접근하면 데이터의 일관성이 깨질 수 있으므로, 이를 방지하기 위한 동기화 메커니즘이 필요하다.
이런 공유 자원을 접근하는 코드 영역을 임계 구역이라고 한다. 임계 구역은 한 번에 하나의 프로세스나 스레드만이 실행할 수 있어야 하는 부분이므로, 두 개 이상의 프로세스가 동시에 임계 구역을 실행하면 문제가 발생할 수 있다.
< 상호 배제 >
이러한 문제를 방지하기 위한 주요 동기화 기법 중 하나가 상호 배제 이다. 상호 배제는 한 번에 하나의 프로세스만이 임계 구역을 실행하도록 하는 동기화 기법이다. 상호 배제는 다양한 방법으로 구현될 수 있으며, 그 중 일부는 세마포어,뮤텍스,모니터 등의 동기화 메커니즘을 사용한다.
CPU는 컴퓨터의 두뇌이다. CPU는 메모리에 저장된 명령어를 읽어 들이고, 읽어 들인 명령어를 해석하고, 실행하는 부품이다. 이 말은 아직 생소할지도 모르겠다.
CPU의 역할과 작동 원리를 구체적으로 이해하기 위해서는 CPU 내부 구성 요소를 알아야 한다.
이 책에서 학습할 CPU 내부 구성 요소 중 가장 중요한 세 가지는 산술논리연산장치(ALU: Arithmetic Logic Unit(이하 ALU), 레지스터(register),제어장치(CU;control unit)이다.
①.ALU : 쉽게 말해 "계산기" 이다. 계산만을 위해 존재하는 부품이다. 컴퓨터 내부에서 수행되는 대부분의 계산은 ALU가 도맡아 수행 한다.
②.Register : CPU 내부의 작은 임시 저장 장치이다. 프로그램을 실행하는 데 필요한 값들을
"임시 저장"한다. cpu 안에는 여러 개의 레지스터가 존재하고, 각기 다른 이름과 역할을 가지고 있다.
③.CU : 제어장치는 제어 신호(control signal)을 내보내고 명령어를 해석하는 장치이다. 여기서 제어 신호란 컴퓨터 부품들을 관리, 작동시키기 위한 일종의 전기 신호이다. 제어 신호에 대해서는 이후에 자세히 설명할 예정, 지금은 아래의 내용만 이해하고 있어도 무방.
CPU가 메모리에 저장된 값을 "읽고" 싶을 땐 메모리를 향해 "메모리 읽기"라는 "제어 신호"를 보낸다.
CPU가 메모리에 어떤 값을"저장" 하고싶을 땐 메모리를 향해 "메모리 쓰기"라는 "제어 신호"를 보낸다.
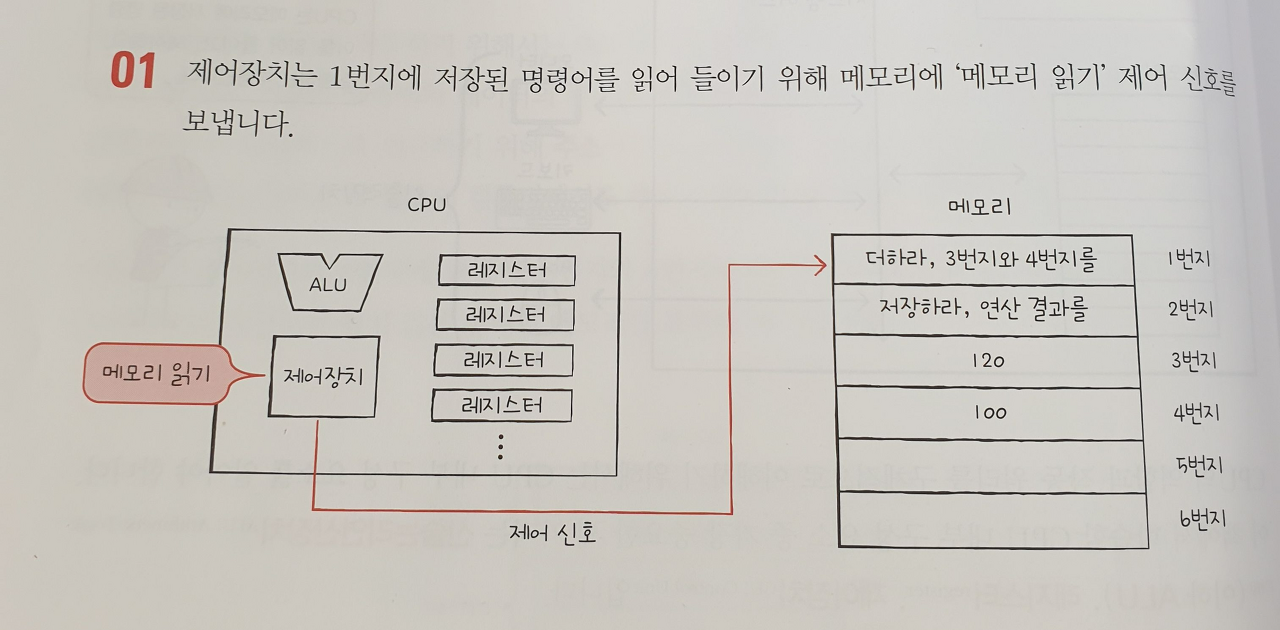
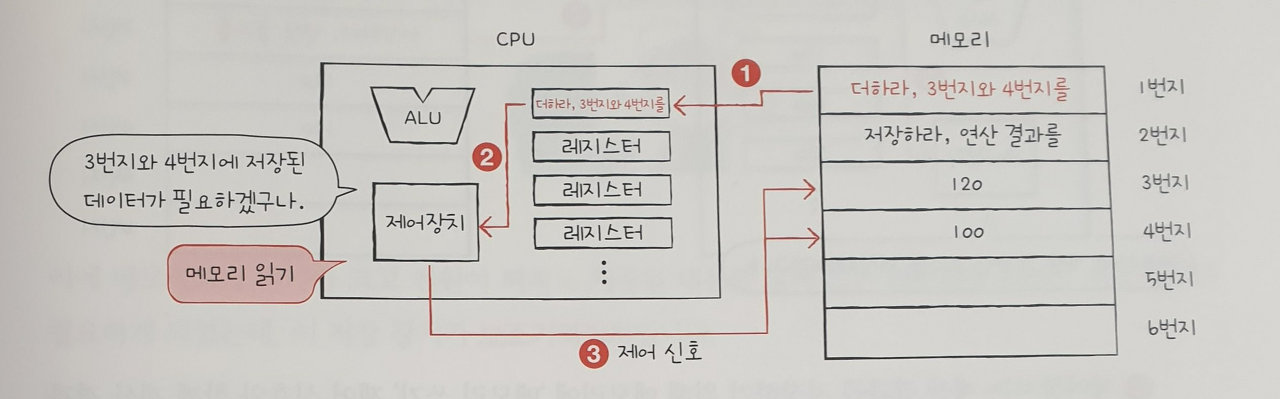
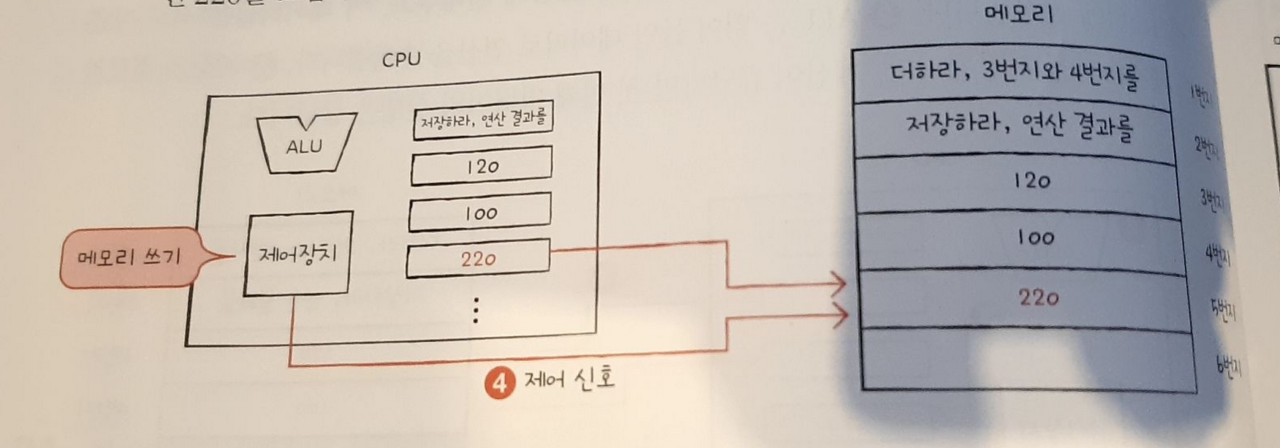
간단한 예시를 통해 cpu를 구성하는 세 가지 부품의 역할을 알아보자. 앞서 살펴본 메모리 그림을 다시 보자. 1번지 부터 2번지까지 명령어가 저장되어 있다. cpu가 이 두 개의 명령을 어떻게 실행하는지 살펴보자.(여기서는 간략화된 예시로 이후 자세히 학습할 예정이니.외우려 하지 말고 흐름만 따라오길 바란다)
01.
제어장치는 1번지에 저장된 명령어를 읽어 들이기 위해 메모리에 '메모리 읽기'제어 신호를 보낸다.
02.
① 메모리는 1번지에 저장된 명령어를 "CPU"에 건네주고, 이 명령어는 레지스터에 저장된다. ② 제어장치는 읽어 들인 명령어를 해석한 뒤 3번지와 4번지에 저장된 데이터가 필요하다고 판단한다. ③. 제어장치는 3번지와 4번지에 저장된 데이터를 읽어 들이기 위해 메모리에 '메모리 읽기' 제어 신호를 보낸다.
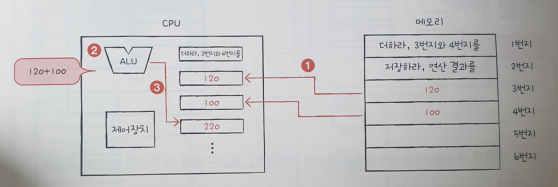
03.
① 메모리는 3번지와 4번지에 저장된 데이터를 CPU에 건네주고, 이 데이터들은 서로 다른 레지스터에 저장된다. ②.ALU는 읽어 들인 데이터로 연산을 수행한다. ③.계산=의 결괏값은 "레지스터"에 저장된다.
계산이 끝났다면 첫 번째 명령어의 실행은 끝난다.
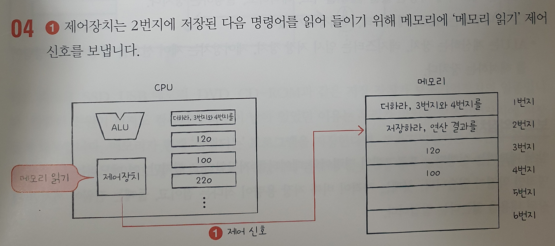
04.
① 제어장치는 2번지에 저장된 다음 명령어를 읽어 들이기 위해 메모리에 '메모리 읽기' 제어 신호를 보낸다.
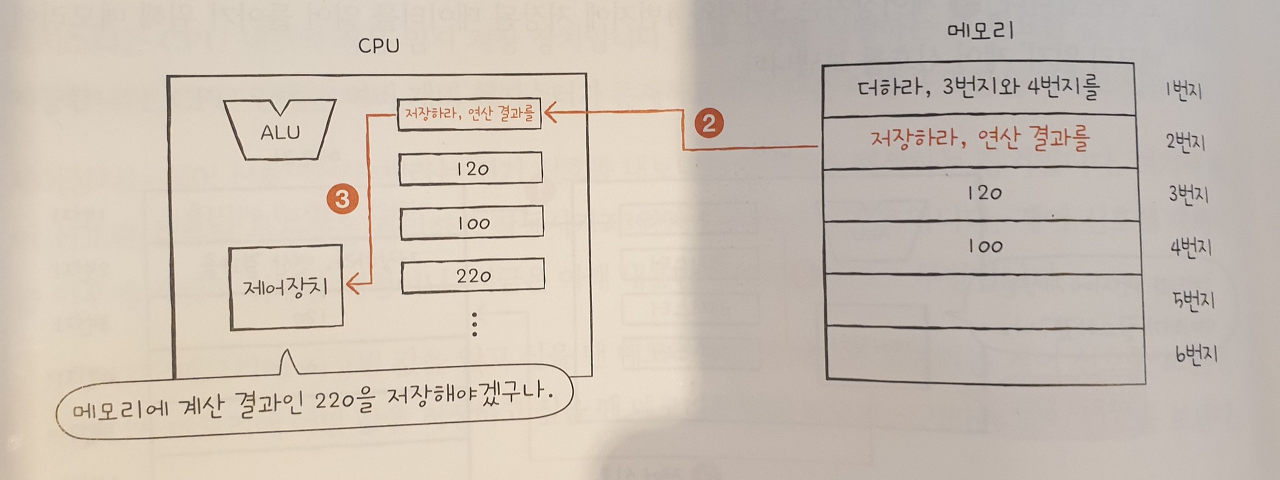
② 메모리는 2번지에 저장된 명령어를 CPU에 건네주고, 이 명령어는 레지스터에 저장된다.
③.제어장치는 이 명령어를 해석한 뒤 메모리에 계산 결과를 저장해야 한다고 판단한다.
④.제어장치는 계산 결과를 저장하기 위해 메모리에 "메모리 쓰기"제어 신호와 함께 계산 결과인 220을 보낸다.메모리가 계산 결과를 저장하면 두 번째 명령어의 실행도 끝난다.
요약
1.CPU는 메모리에 저자된 값을 읽어 들이고, 해석하고, 실행하는 장치이다.
2.CPU 내부에는 ALU,레지스터,제어장치가 있다.
3.ALU는 계산하는 장치, 레지스터는 임시 저장 장치, 제어장치는 제어 신호를 발생시키고 명령어를 해석하는 장치이다.