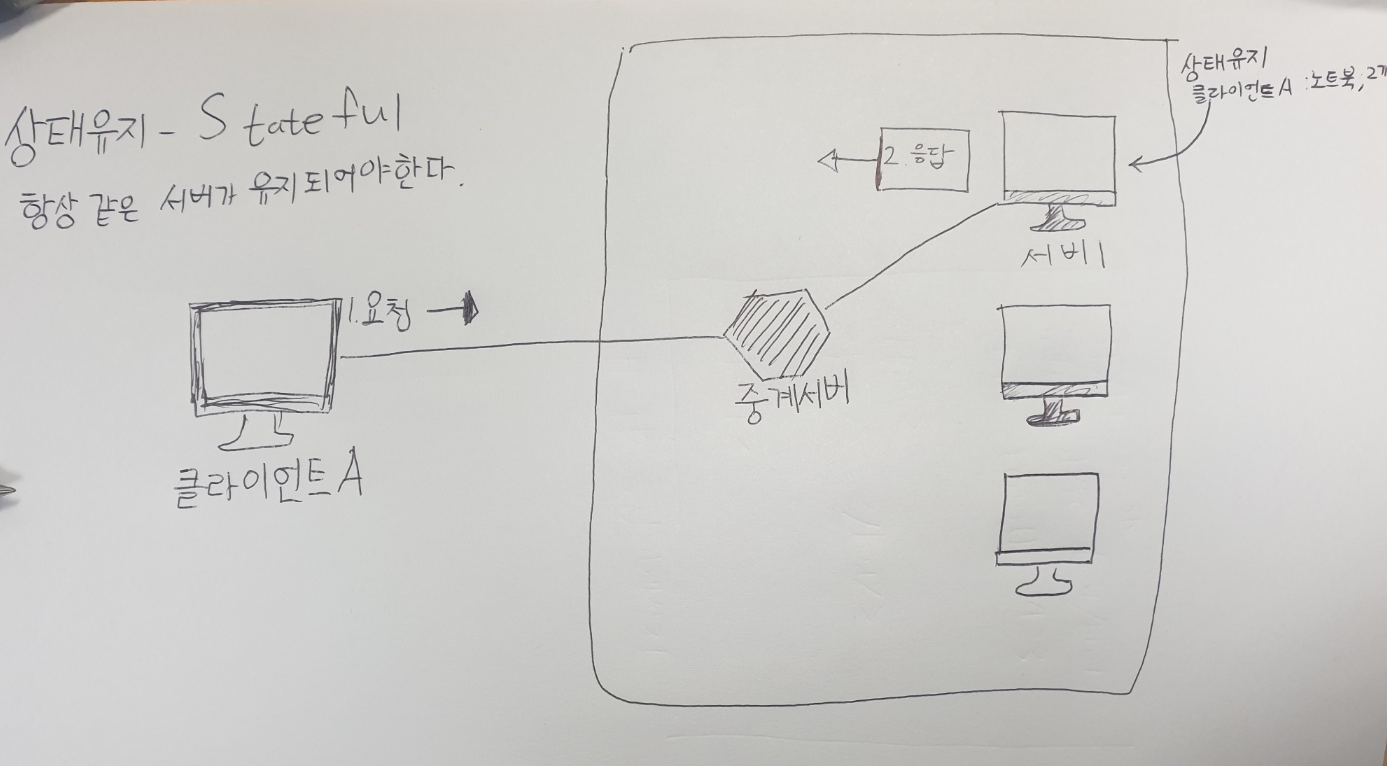
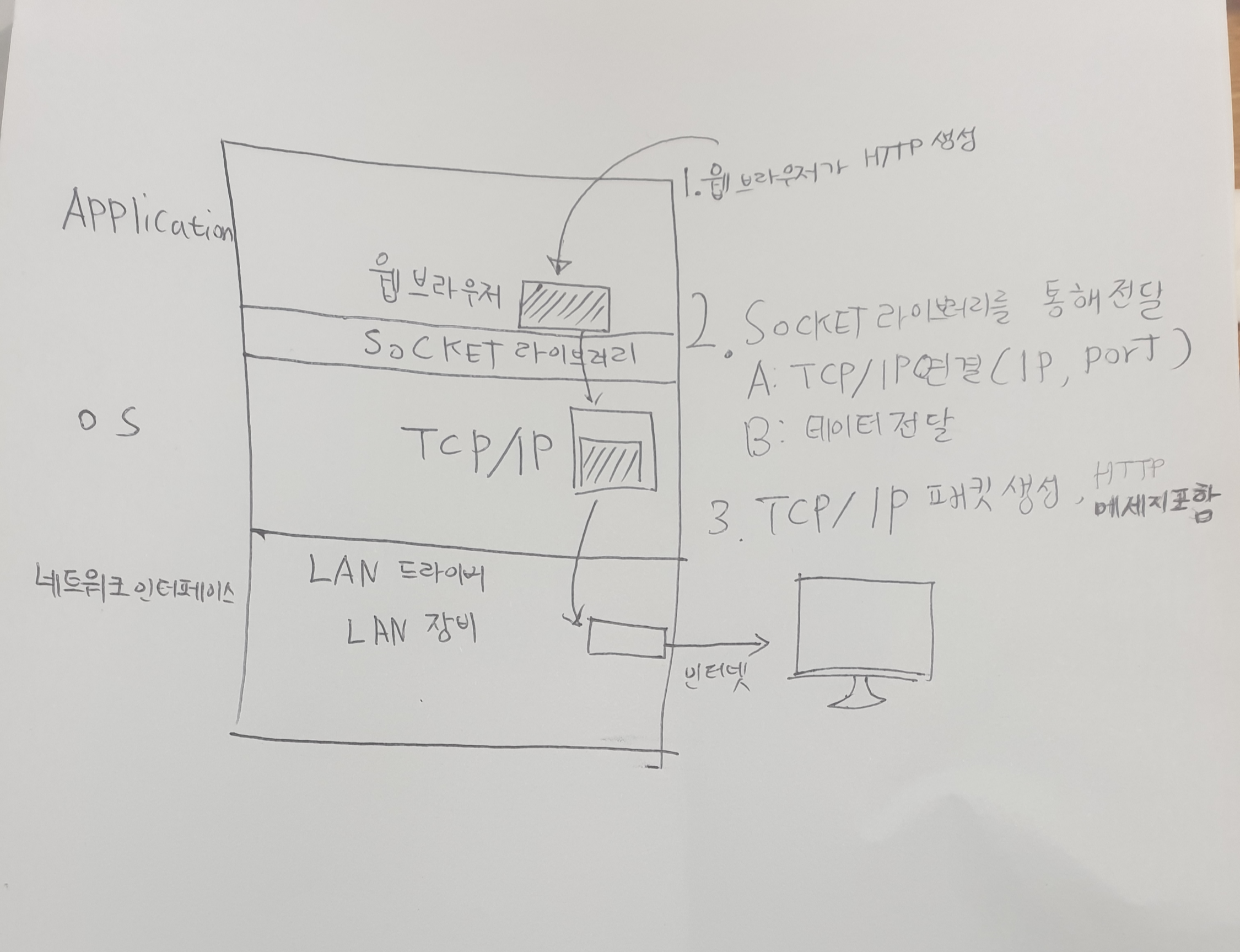
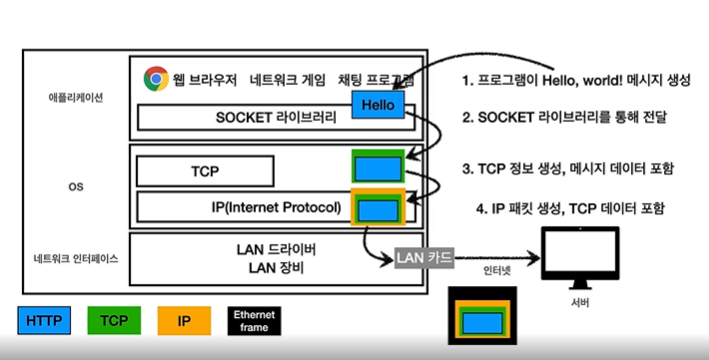
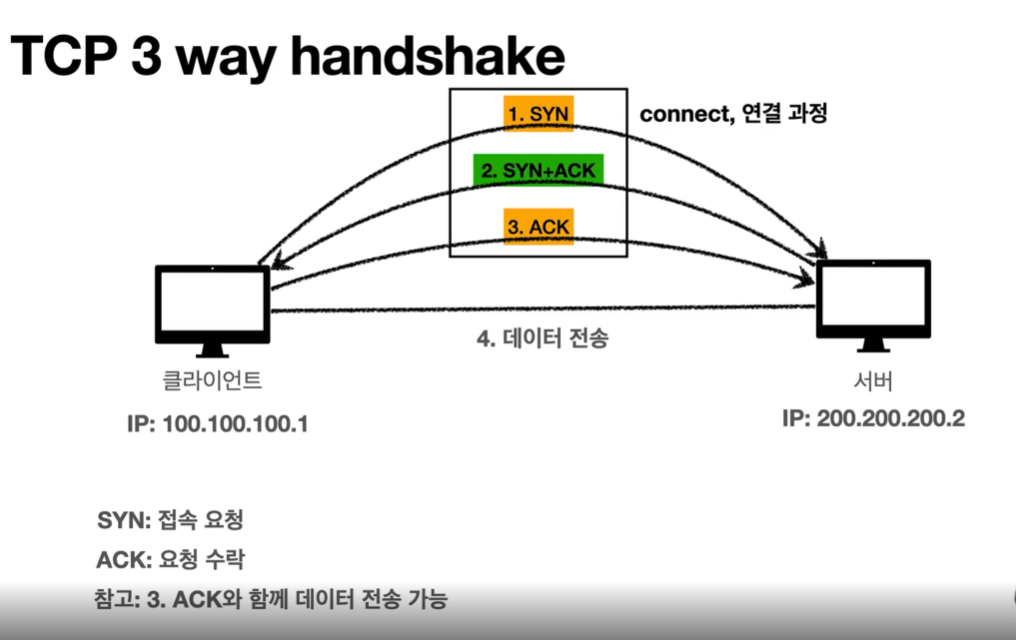
html에서 이미지를 보는 방법은 두 가지가 있다.
1.이미 렌더링된 이미지
2.클릭 시 다운로드
CODE가 있는데, 사이트 내에서 "공통"으로 뽑기 위해 테이블 자체를 둔 것이다.
CODE를 보고 상품관리에 등록된 거구나 등 유추해야 한다.
RID는 게시판의 몇번글에 대한 첨부파일이다.
파일 첨부는 coomon->entity->uploadfile
에서 DTO부터 먼저 만들어보자
UploadFileId
code
rid
store_filename
upload_filename
fsize
ftype
cdate
udate
이렇게 DTO를 만들고
UploadFileDAO
package com.kh.app.domain.common.dao;
import com.kh.app.domain.entity.UploadFile;
import java.util.List;
import java.util.Optional;
public interface UploadFileDAO {
/**
* 업로드 파일 등록 - 단건
* @param uploadFile
* @return 파일Id
*/
Long addFile(UploadFile uploadFile);
/**
* 업로드 파일 등록 - 여러건
* @param uploadFiles
*/
void addFiles(List uploadFiles);
/**
* 업로드파일조회
* @param code
* @param rid
* @return
*/
List findFilesByCodeWithRid(String code,Long rid);
/**
* 첨부파일조회
* @param uploadfileId
* @return
*/
Optional findFileByUploadFileId(Long uploadfileId);
/**
* 첨부파일 삭제 by uplaodfileId
* @param uploadfileId 첨부파일아이디
* @return 삭제한 레코드수
*/
int deleteFileByUploadFildId(Long uploadfileId);
/**
* 첨부파일 삭제 By code, rid
* @param code 첨부파일 분류코드
* @param rid 첨부파일아이디
* @return 삭제한 레코드수
*/
int deleteFileByCodeWithRid(String code, Long rid);
}
package com.kh.app.domain.common.dao;
import com.kh.app.domain.entity.UploadFile;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.dao.EmptyResultDataAccessException;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.namedparam.*;
import org.springframework.jdbc.support.GeneratedKeyHolder;
import org.springframework.jdbc.support.KeyHolder;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Map;
import java.util.Optional;
@Slf4j
@Repository
@RequiredArgsConstructor
public class UploadFileDAOImpl implements UploadFileDAO{
private final NamedParameterJdbcTemplate template;
//업로드파일 등록-단건
@Override
public Long addFile(UploadFile uploadFile) {
StringBuffer sql = makeAddFileSql();
SqlParameterSource param = new BeanPropertySqlParameterSource(UploadFile.class);
KeyHolder keyHolder = new GeneratedKeyHolder();
template.update(sql.toString(),param,keyHolder,new String[]{"uploadfile_id"});
return keyHolder.getKey().longValue();
}
//업로드파일 등록-여러건
@Override
public void addFiles(List uploadFiles) {
StringBuffer sql = makeAddFileSql();
if(uploadFiles.size() == 1){
SqlParameterSource param = new BeanPropertySqlParameterSource(uploadFiles.get(0));
template.update(sql.toString(),param);
}else {
SqlParameterSource[] params = SqlParameterSourceUtils.createBatch(uploadFiles);
//배치 처리 : 여러건의 갱신작업을 한꺼번에 처리하므로 단건처리할때보다 성능이 좋다.
template.batchUpdate(sql.toString(), params);
}
}
private StringBuffer makeAddFileSql() {
StringBuffer sql = new StringBuffer();
sql.append("INSERT INTO uploadfile ( ");
sql.append(" uploadfile_id, ");
sql.append(" code, ");
sql.append(" rid, ");
sql.append(" store_filename, ");
sql.append(" upload_filename, ");
sql.append(" fsize, ");
sql.append(" ftype ");
sql.append(") VALUES ( ");
sql.append(" uploadfile_uploadfile_id_seq.nextval, ");
sql.append(" :code, ");
sql.append(" :rid, ");
sql.append(" :store_filename, ");
sql.append(" :upload_filename, ");
sql.append(" :fsize, ");
sql.append(" :ftype ");
sql.append(") ");
return sql;
}
//조회
@Override
public List findFilesByCodeWithRid(String code, Long rid) {
StringBuffer sql = new StringBuffer();
sql.append("SELECT ");
sql.append(" uploadfile_id, ");
sql.append(" code, ");
sql.append(" rid, ");
sql.append(" store_filename, ");
sql.append(" upload_filename, ");
sql.append(" fsize, ");
sql.append(" ftype, ");
sql.append(" cdate, ");
sql.append(" udate ");
sql.append(" FROM uploadfile ");
sql.append(" WHERE CODE = :code ");
sql.append(" AND RID = :rid ");
return template.query(
sql.toString(),
Map.of("code",code,"rid",rid),
BeanPropertyRowMapper.newInstance(UploadFile.class));
}
//첨부파일 조회
@Override
public Optional findFileByUploadFileId(Long uploadfileId) {
StringBuffer sql = new StringBuffer();
sql.append(" select * ");
sql.append(" from uploadfile ");
sql.append(" where uploadfile_id = :uploadfile_id ");
UploadFile uploadFile = null;
try {
Map param = Map.of("uploadfile_id", uploadfileId);
uploadFile = template.queryForObject(sql.toString(),param,BeanPropertyRowMapper.newInstance(UploadFile.class));
return Optional.of(uploadFile);
}catch (EmptyResultDataAccessException e){
return Optional.empty();
}
}
// 첨부파일 삭제 by uplaodfileId
@Override
public int deleteFileByUploadFildId(Long uploadfileId) {
StringBuffer sql = new StringBuffer();
sql.append("delete from uploadfile ");
sql.append(" where uploadfile_id = :uploadfile_id ");
return template.update(sql.toString(), Map.of("uploadFile_id",uploadfileId));
}
// 첨부파일 삭제 by code, rid
@Override
public int deleteFileByCodeWithRid(String code, Long rid) {
StringBuffer sql = new StringBuffer();
sql.append("delete from uploadfile ");
sql.append(" where code = :code ");
sql.append(" and rid = :rid ");
return template.update(sql.toString(),Map.of("code",code,"rid",rid));
}
}
SqlParameterSource[] params = SqlParameterSourceUtils.createBatch(uploadFiles);는 uploadfile의 정보를 배열로 담은 것이다.
template.batchUpdate(sql.toString(), params);이건 배열에 담긴 걸 한 꺼번에 처리한다는 뜻이다.
배치처리란 insert문 여러 개를 한 꺼번에 쏘는 것이다.
이번엔 Test를 할 차례다.
ctrl+shift+T로 구조를 똑같게 테스트 환경을 만들 수 있다
@SpringBootTest
UploadDAOImplTest {
@Autowired
private UploadFileDAO uploadFileDAO
@Test
@Displayname("단건 첨부")
}
IOC는 개발자가 직접 객체를 생성하지 않고, 프레임워크가 직접 생성하는 객체다.
DI는 private UploadFileDAO uploadFileDAO즉 DAO에 담긴 객체를 내게 달라는 뜻이다.
@RequiredArgsConstrutor는
final 생성자를 재료로 삼아서, 매개변수를 만들어 준다.
그렇게 되면 객체 연관관계 , 즉 sql의 pk,fk와 같이 app같에도 객체와 객체사이 참조가 되버린다.
여기선 uploadFileDAOImpl과 NamedParameterJDBCTemplate이 그 관계다.
insert into code (code_id,decode,pcode_id,useyn) values('F01','첨부파일',null,'Y');
insert into code (code_id,decode,pcode_id,useyn) values('F010301','상품관리_일반','F01','Y');
insert into code (code_id,decode,pcode_id,useyn) values('F010302','상품관리_이미지','F01','Y');
F01은 파일 첨부다.
스프링프레임이 관리하는 객체를 Bean이라고 한다.
이제 SaveForm에서
private List<MultipartFile> attachFiles; // 일반파일
private List<MultipartFile> imageFiles; // 이미지파일 이렇게 해서 이미지,파일을 받을 수 있다.
단건으로 할려면
MulipartFile attachFile로 하면 됨.
그럼 saveform요청메세지 body에 담겨져 온다.
multipartFileTouploadFile
여기서 AttachfileType aa = AttachFileType.F010301
로 해서 이넘 타입의 상수 값을 가질 수 있다 .
여기서 aa앞에 있는 AttachfileType의 값만 소환 가능.
Enum은 한정된 값을 정한 타입이다. ex)요일,성별 등 정해진 값.
@Transaction은 논리적 최소 단위다 2 or not 즉 2개의 로직이 실행되지않으면 아예 실행안되는 것이다.
<div><label for="">일반첨부</label><input type="file"></div>
여기서 파일 여러 개 추가 할려면
<div><label for="">일반첨부</label><input type="file" multiple></div>
이렇게 하면 된다.