클라이언트는 데이터베이스에 직접 접근할 수 없다. 그러니 이 역시도 API를 구현해볼 수 있도록 해야한다.
여기서는 블로그 글을 조회하기 위한 API를 구현한다. 모든 글을 조회하는 API,글 내용을 조회하는 API를 순서대로 구현한다.
<①.서비스 메서드 코드 작성하기>
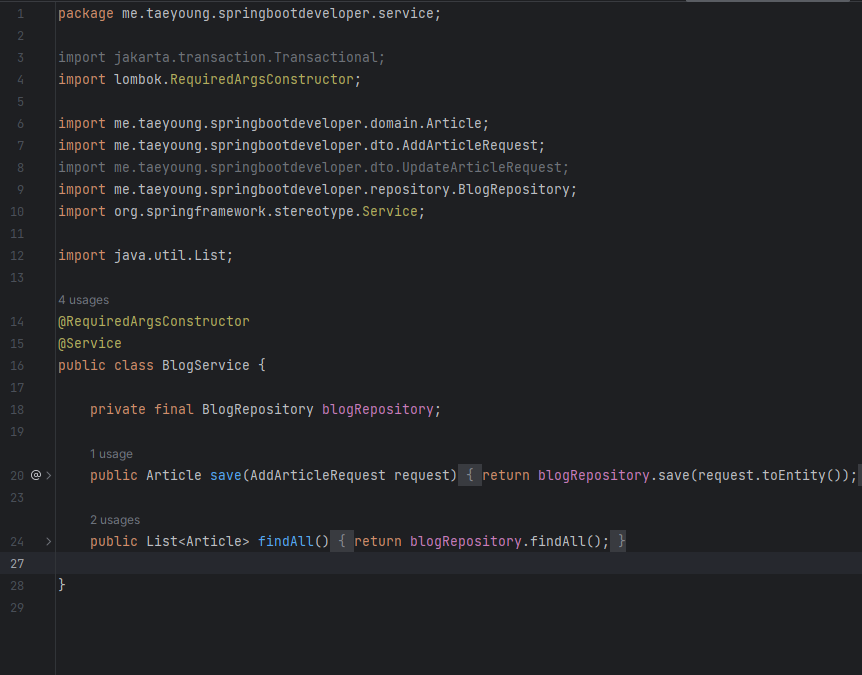
BlogService.java 파일을 열어 데이터 베이스에 저장되어 있는 글을 모두 가져오는 findAll()메서드를 추가한다.
JPA 지원 메서드인 findAll()을 호출해 article 테이블에 저장되어 있는 모든 데이터를 조회한다. 이제 요청을 받아 서비스에 전달하는 컨트롤러를 만들면 된다.
<②.컨트롤러 메서드 코드 작성하기>
/api/articles GET 요청이 오면 글 목록을 조회할 findAllArticles() 메서드를 작성한다. 이 메서드는 전체 글 목록을 조회하고 응답하는 역할을 한다.
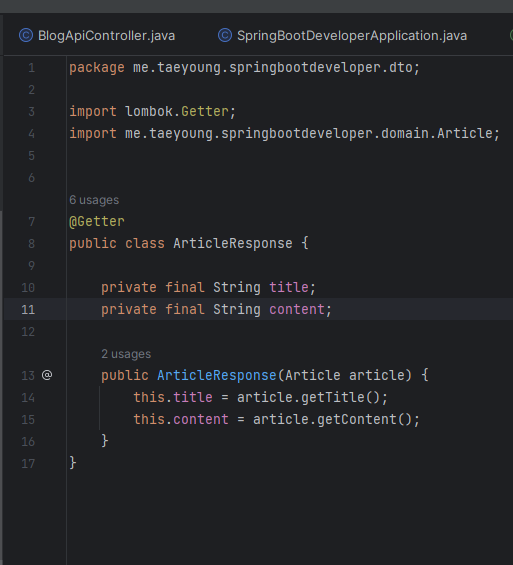
1단계 : 응답을 위한 DTO를 먼저 작성한다. dto 디렉터리에 ArticleResponse.java 파일을 생성하고 다음과 같이 코드를 작성하면 된다.
글은 제목과 내용 구성이므로 해당 필드를 가지는 클래스를 만든 다음, 엔티티를 인수로 받는 생성자를 추가 했다.
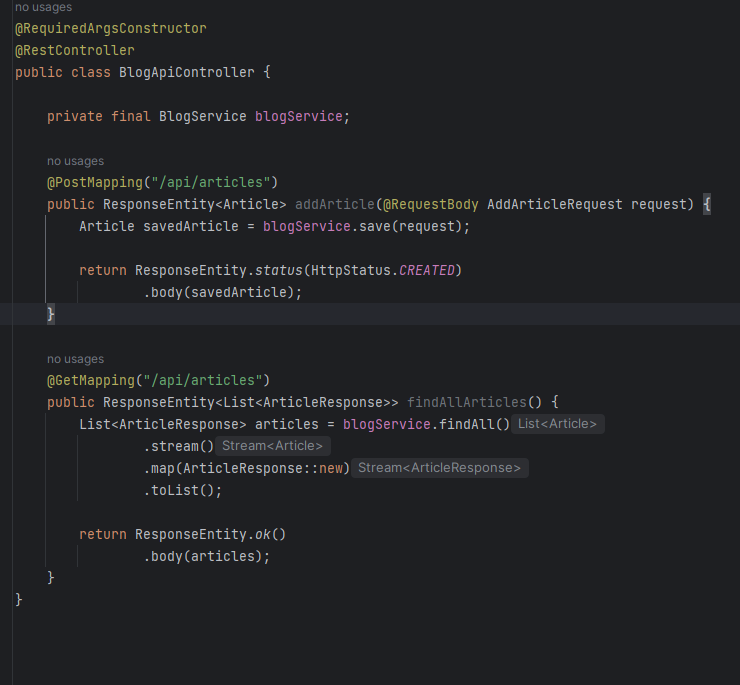
2단계 : Controller 디렉터리에 있는 BlogApiController.java 파일을 열어 전체 글을 조회한 뒤 반환하는 findAllArticles()메서드를 추가한다.
/api/articles GET 요청이 오면 글 전체를 조회하는 findAll() 메서드를 호출한 다음 응답용 객체인 ArticleResponse로 파싱해 body에 담아 클라이언트에게 전송한다. 이 코드에는 스트림을 적용하였다. (스트림은 자바 8의 기능으로 여러 데이터가 모여있는 컬렉션을 간편하게 처리하기 위한 기능이다.)
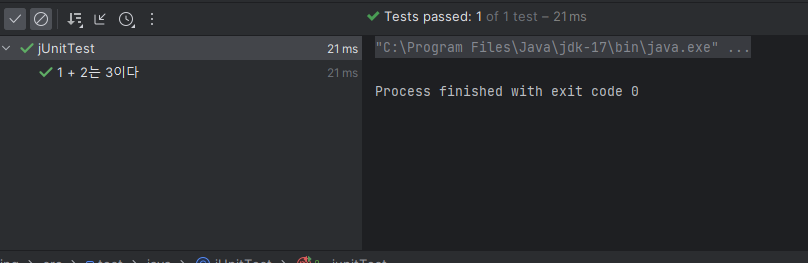
개발을 하면서 테스트 과정을 계속 거쳐야 하는데, 매번 H2 콘솔 등에 접속해 쿼리를 입력해 데이터가 저장되는지. 실제로 들어 있는지 확인하는 등 이런 방식으로 테스트하려면 매우 불편하다. 이런 작업을 줄여줄 테스트 코드가 있다.
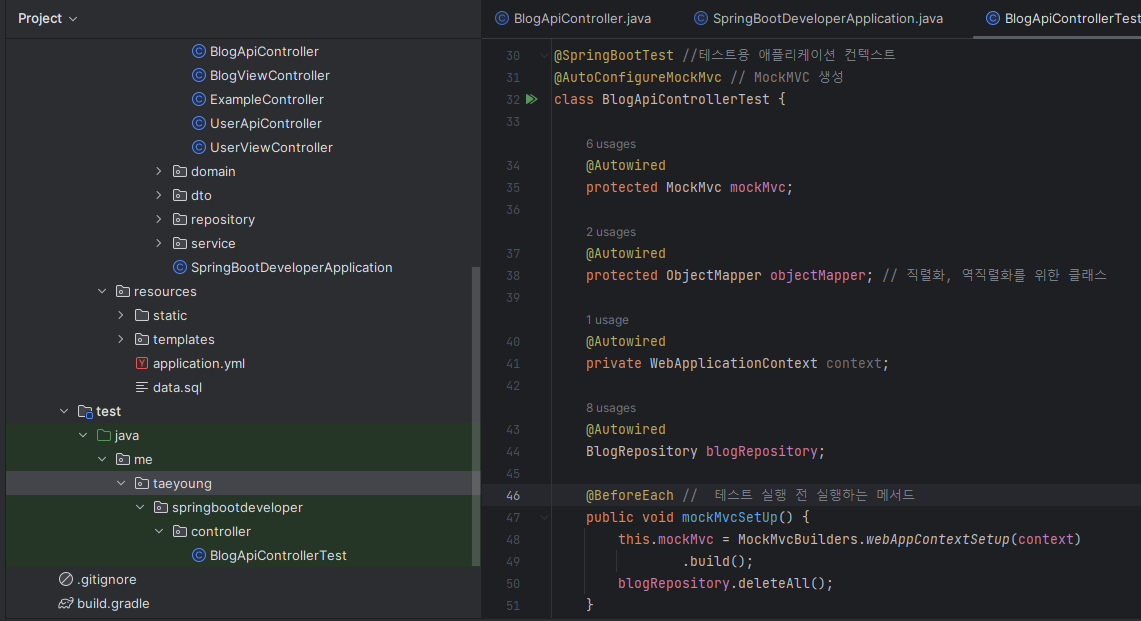
BlogApiController Class에 Alt+Enter를 누르고 [Create Test]를 누르면 테스트 생성 창이 열린다. 기본값을 그대로 두고 테스트 코드 파일을 생성하면 된다. 이 과정을 마치면 /test/java/패키지/아래에 BlogApiControllerTest.java 파일이 만들어 진다. 이 파일을 수정해보겠다.
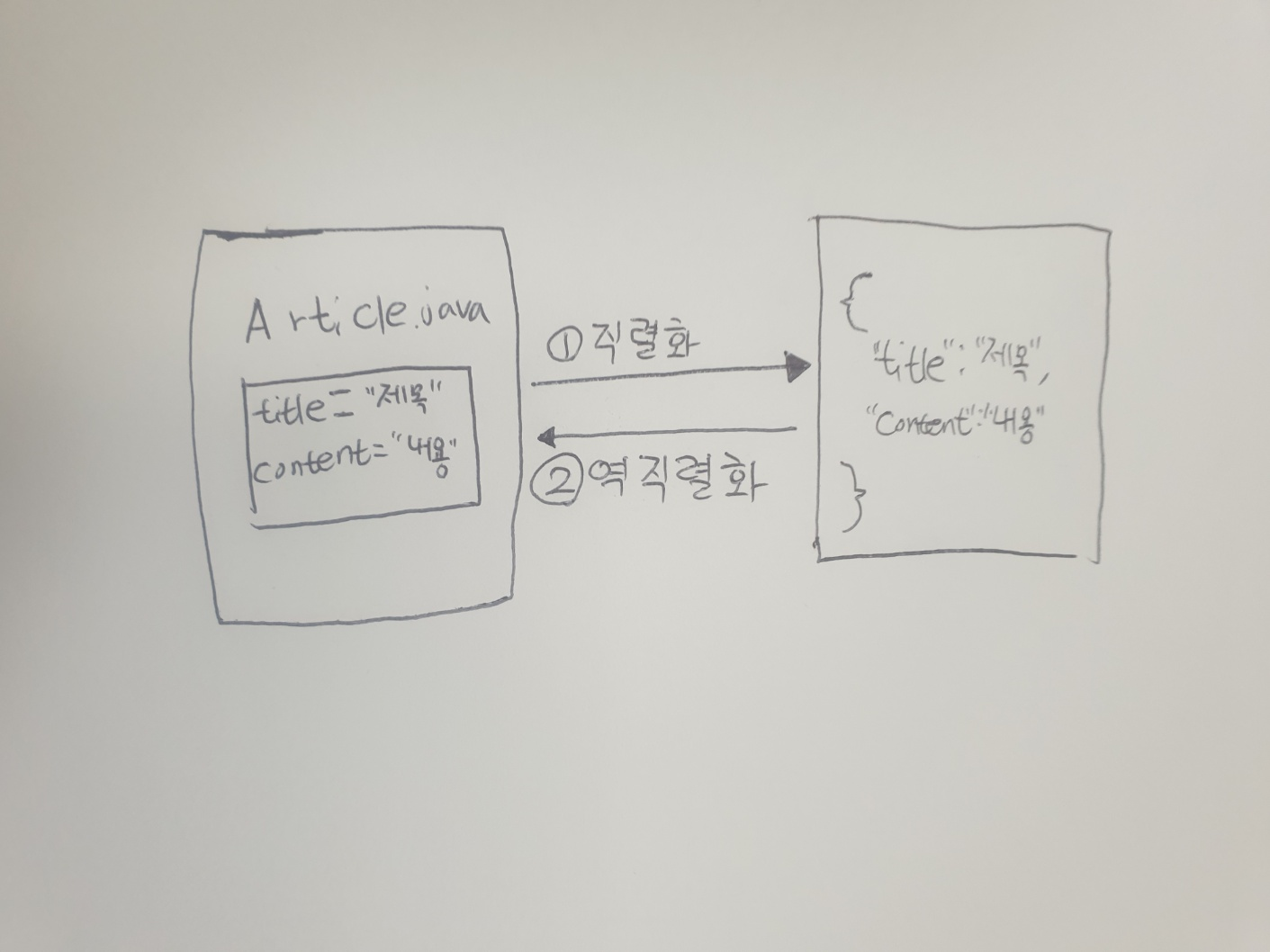
ObjectMapper 클래스로 만든 객체는 자바 객체를 JSON 데이터로 변환하는 직렬화(serialization)또는 반대로 JSON 데이터를 자바에서 사용하기 위해 자바 객체로 변환하는 역직렬화(deserialization)할 때 사용한다.
< 자바 직렬화와 역직렬화 >
HTTP에서는 JSON을, 자바에서는 객체를 사용한다. 하지만 서로 형식이 다르기 때문에 형식에 맞게 변환하는 작업이 필요하다. 이런 작업들을 직렬화,역직렬화라고 한다. ① 직렬화란 자바 시스템 내부에서 사용되는 객체를 외부에서 사용하도록 데이터를 변환하는 작업을 이야기한다. 예를 들어 title은 "제목", content는 "내용"이라는 값이 들어 있는 객체가 있다고 가정을 들겠다. 이때 이 객체를 JSON 형식으로 직렬화할 수 있다. ② 역직렬화는 직렬화의 반대이다. 외부에서 사용하는 데이터를 자바 객체 형태로 변환하는 작업을 이야기한다. JSON 형식의 값을 자바 객체에 맞게 변환하는 것도 역직렬화 이다.
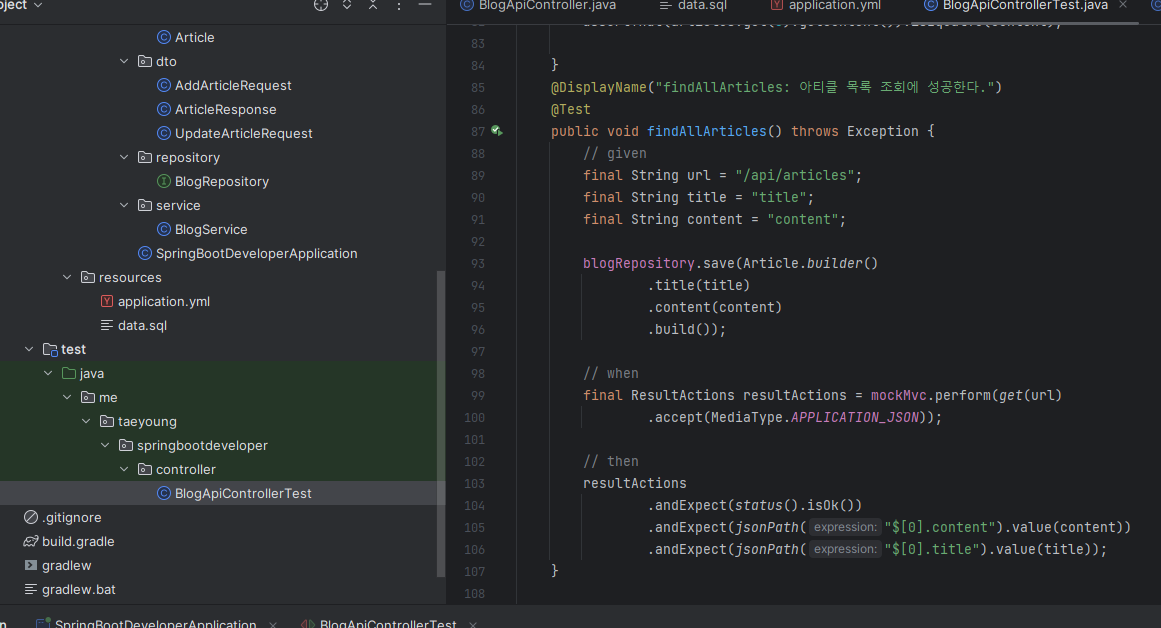
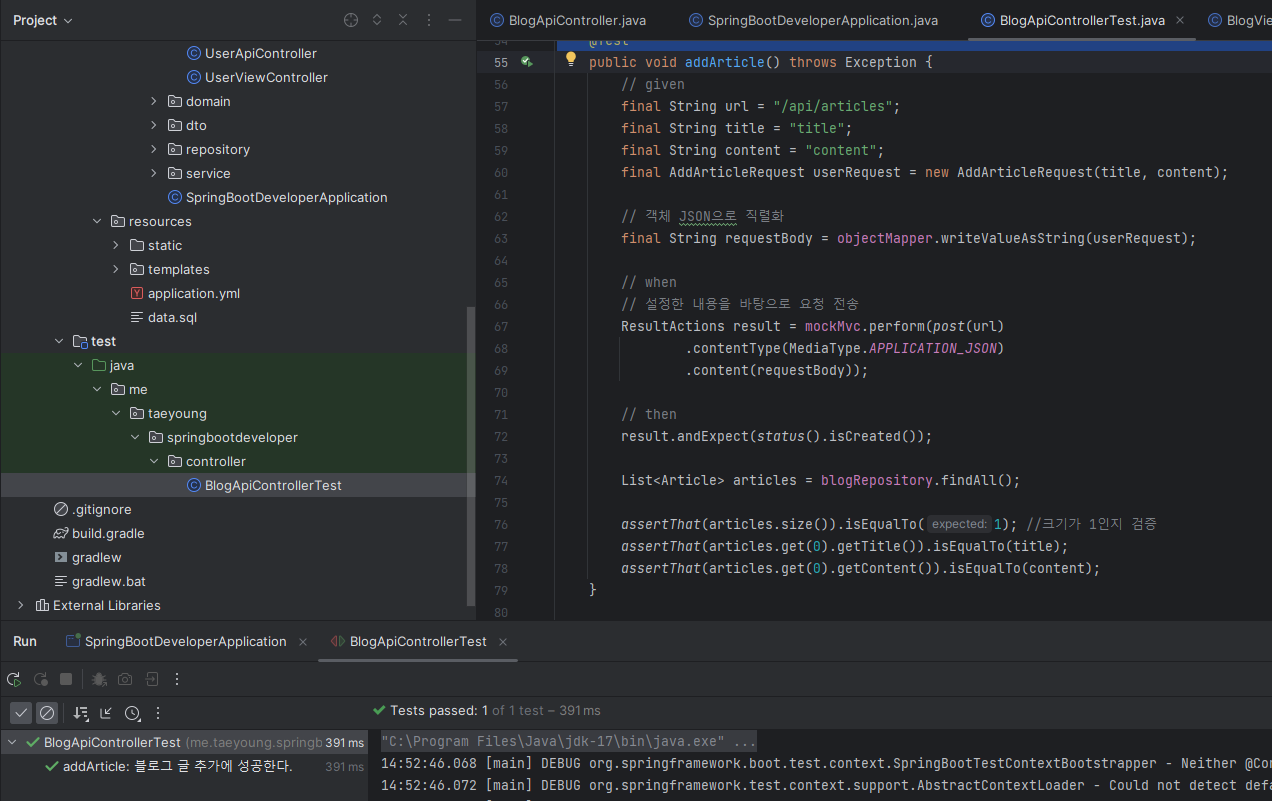
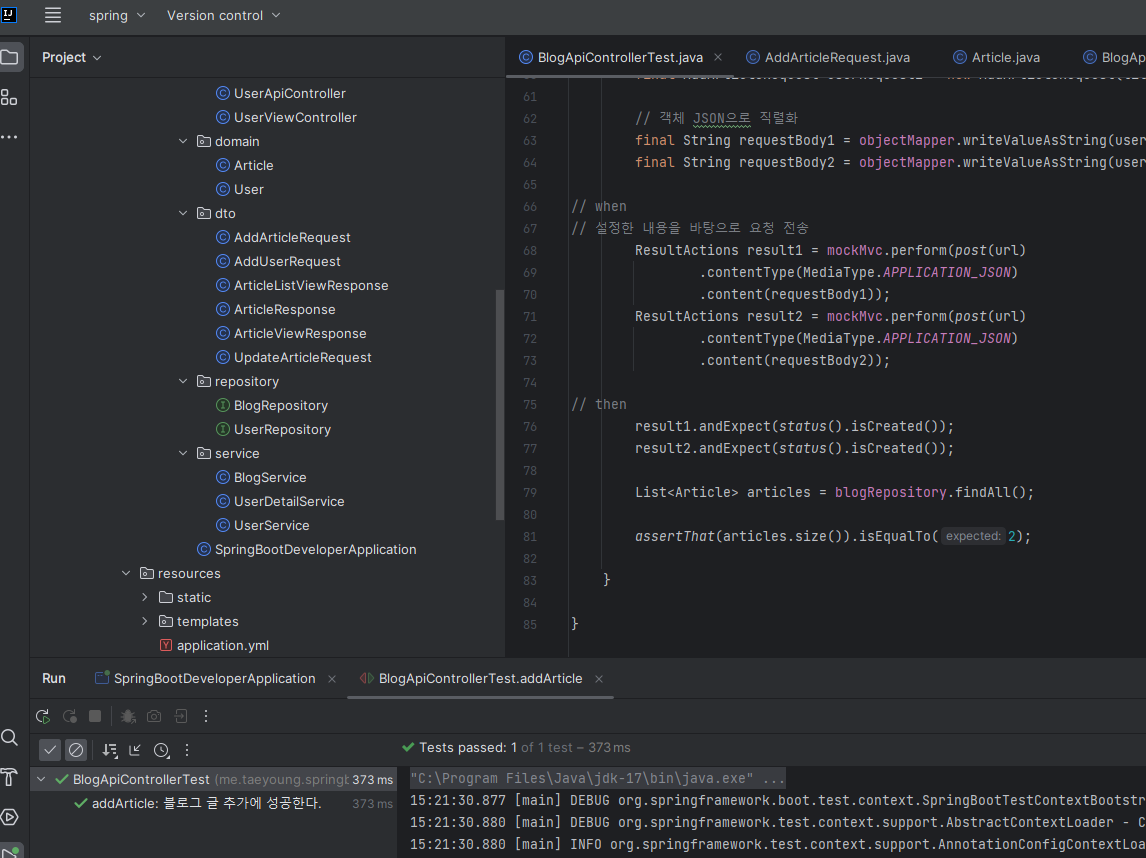
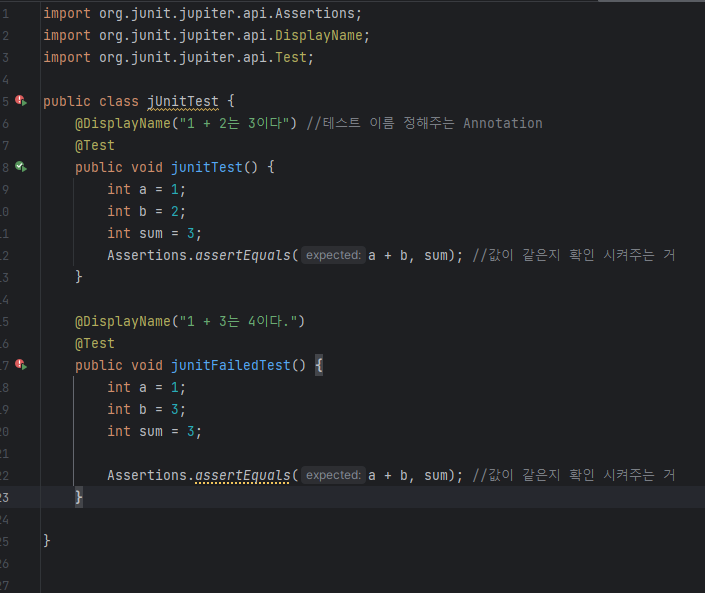
이제 블로그 글 생성 API를 테스트하는 코드를 작성하면 된다. given-when-then 패턴을 생성할 코드의 내용은 다음과 같다.
BlogApiControllerTest.java 파일에 작성하면 된다.
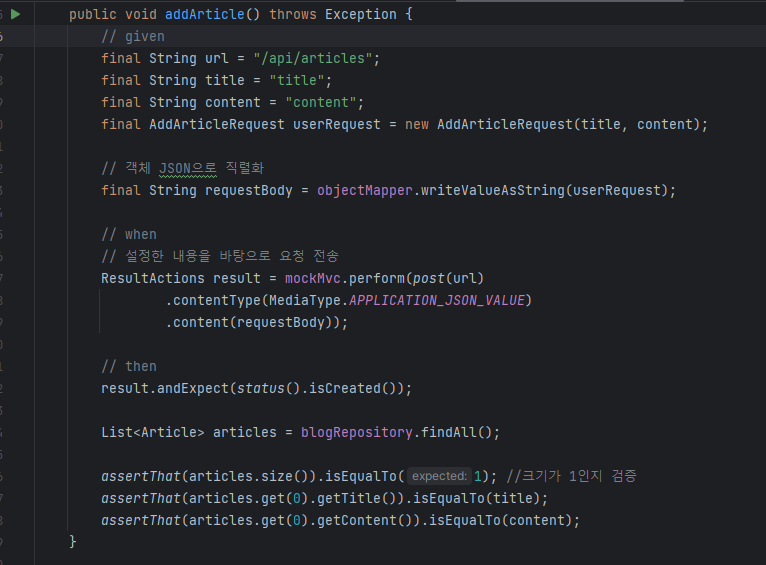
Given
블로그 글 추가에 필요한 요청 객체를 만든다.
When
블로그 글 추가 API에 요청을 보낸다. 이때 요청 타입은 JSON이며, given절에서 미리 만들어준 객체를 요청 본문으로 함께 보낸다.
Then
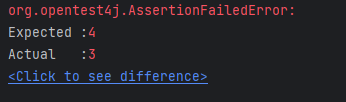
응답 코드가 201 Created인지 확인한다. Blog를 전체 조회해 크기가 1인지 확인하고, 실제로 저장된 데이터와 요청 값을 비교한다.
writeValueAsString() 메서드를 사용해서 객체를 JSON으로 직렬화해준다. 그 이후에는 MockMvc를 사용해 HTTP 메서드, URL,요청 본문,요청 타입등을 설정한 뒤 설정한 내용을 바탕으로 테스트 요청을 보낸다. contentType() 메서드는 요청을 보낼 때 JSON, XML등 다양한 타입 중 하나를 골라 요청을 보낸다. 여기에서 JSON 타입의 요청을 보낸다고 명시했다.
assertThat() 메서드로는 블로그 글의 개수가 1인지 확인한다. 자주 사용하는 메서드는 표로 정리하였다.
이전 글에서 엔티티 구성이 끝났으니 API를 하나씩 구현할 예정이다. 구현 과정은 서비스 클래스에서 메서드를 구현하고, 컨트롤러에서 사용할 메서드를 구현한 다음, API를 실제로 테스트할 것이다. 그림으로 보면 다음과 같다.
[서비스 메서드 코드 작성 하기]
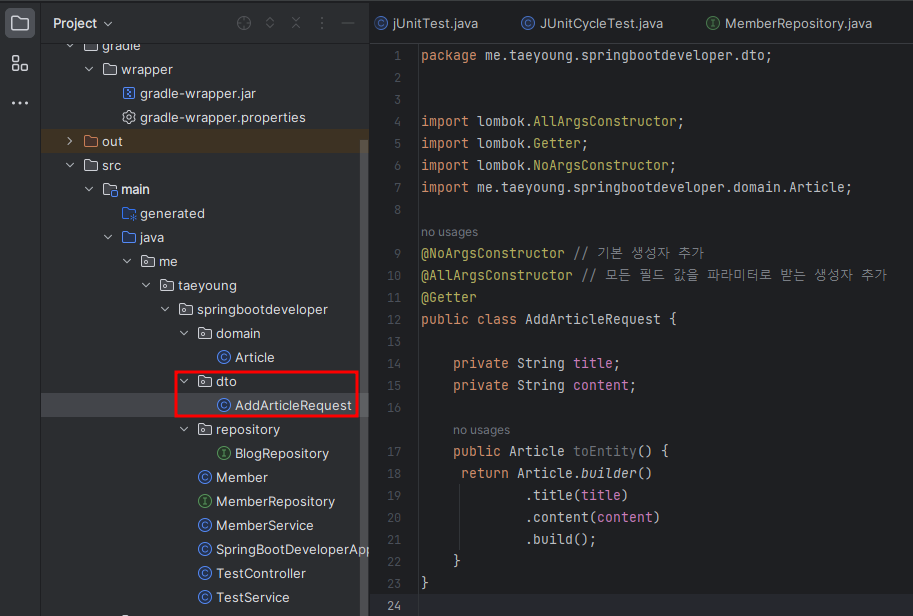
먼저 서비스 계층에 블로그에 글을 추가하는 코드를 작성한다. 서비스 계층에서 요청을 받을 객체인 AddArticleRequest 객체를 생성하고, BlogService 클래스를 생성한 다음에 블로그 글 추가 메서드인 save()를 구현하겠다.
먼저 springbootdeveloper 패키지에 dto 패키지를 생성한 다음, dto 패키지를 컨트롤러에서 요청 본문을 받을 객체인 AddArticleRequest.java 파일을 생성한다. DTO는 계층끼리 데이터를 교환하기 위해 사용하는 객체다. 앞서 DAO를 언급했는데, DAO는 데이터베이스와 연결되고 데이터를 조회하고 수정하는데 사용하는 객체라 데이터 수정과 관련된 로직이 포함되지만 DTO는 단순하게 데이터를 옮기기 위해 사용하는 전달자 역할을 하는 객체이기 때문에 별도의 비즈니스 로직을 포함하지 않는다. 코드를 작성하는 김에 참고로 알아두기 바란다.
toEntity()는 빌더 패턴을 사용해 DTO를 엔티티로 만들어주는 메서드이다. 이 메서드는 추후에 블로그 글을 추가할 때 저장할 엔티티로 변환하는 용도로 사용한다.
springbootdeveloper 패키지에 service 패키지를 생성한 뒤, service 패키지에서 BlogService.java를 생성해 BlogService 클래스를 구현한다.
@RequiredArgsConstructor는 빈을 생성자로 생성하는 롬복에서 지원하는 Annotation이다. final 키워드나 @NotNull이 붙은 필드로 생성자를 만들어준다. @Service 애너테이션은 해당 클래스를 빈으로 서블릿 컨테이너에 등록해준다. save()메서드는 JpaRepository에서 지원하는 저장 메서드 save()로 AddArticleRequest 클래스에 저장된 값들을 article 데이터베이스에 저장한다.
[컨트롤러 메서드 코드 작성하기]
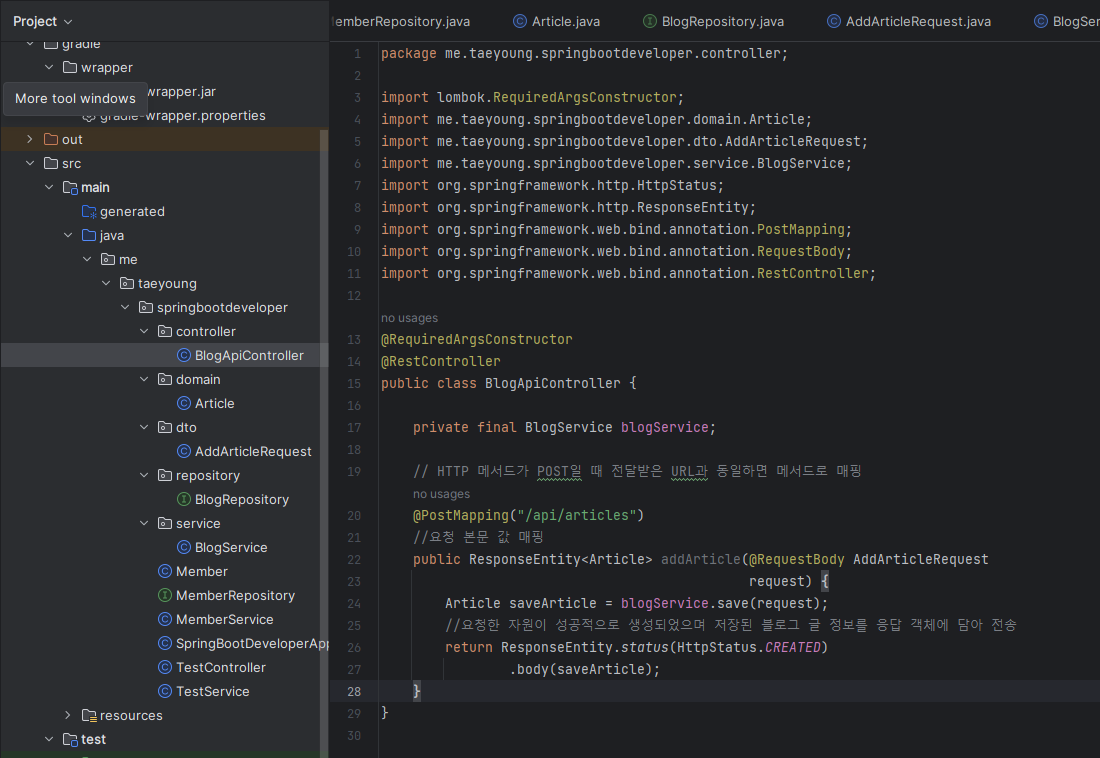
이제 URL에 매핑하기 위한 컨트롤러 메서드를 추가한다. 앞서 컨트롤러 메서드를 구현한 적이 있는데. 다시 복습하자면 컨트롤러 메서드에는 URL 매핑 애너테이션 @GetMapping, @PostMapping, @PutMapping, @DeleteMapping 등을 사용할 수 있다. 이름에서 볼 수 있듯이 각 메서드는 HTTP 메서드에 대응한다. 여기에서는 /api/articles에 POST요청이 오면 @PostMapping을 이용해 요청을 매핑한 뒤, 블로그 글을 생성하는 BlogService의 save() 메서드를 호출한 뒤, 생성된 블로그 글을 반환하는 작업을 할 addArticle() 메서드를 작성한다.
@RestController Annotation을 클래스에 붙이면 HTTP 응답으로 객체 데이터를 JSON 형식으로 반환한다.
@PostMapping() 애너테이션은 HTTP 메서드가 POST일 때 요청받은 URL와 동일한 메서드와 매핑한다.
지금의 경우 /api/articles는 addArticle()메서드에 매핑한다.
@RequestBody 애너테이션은 HTTP를 요청할 때 응답에 해당하는 값을 @RequestBody 애너테이션이 붙은 대상 객체인 AddArticleRequest에 매핑한다. ResponseEntity.status().body()는 응답 코드로 201, 즉, Created를 응답하고 테이블에 저장된 객체를 반환한다.
Reference : Reference : 출처 :스프링 부트 3 백엔드 개발자 되기 - 자바 편
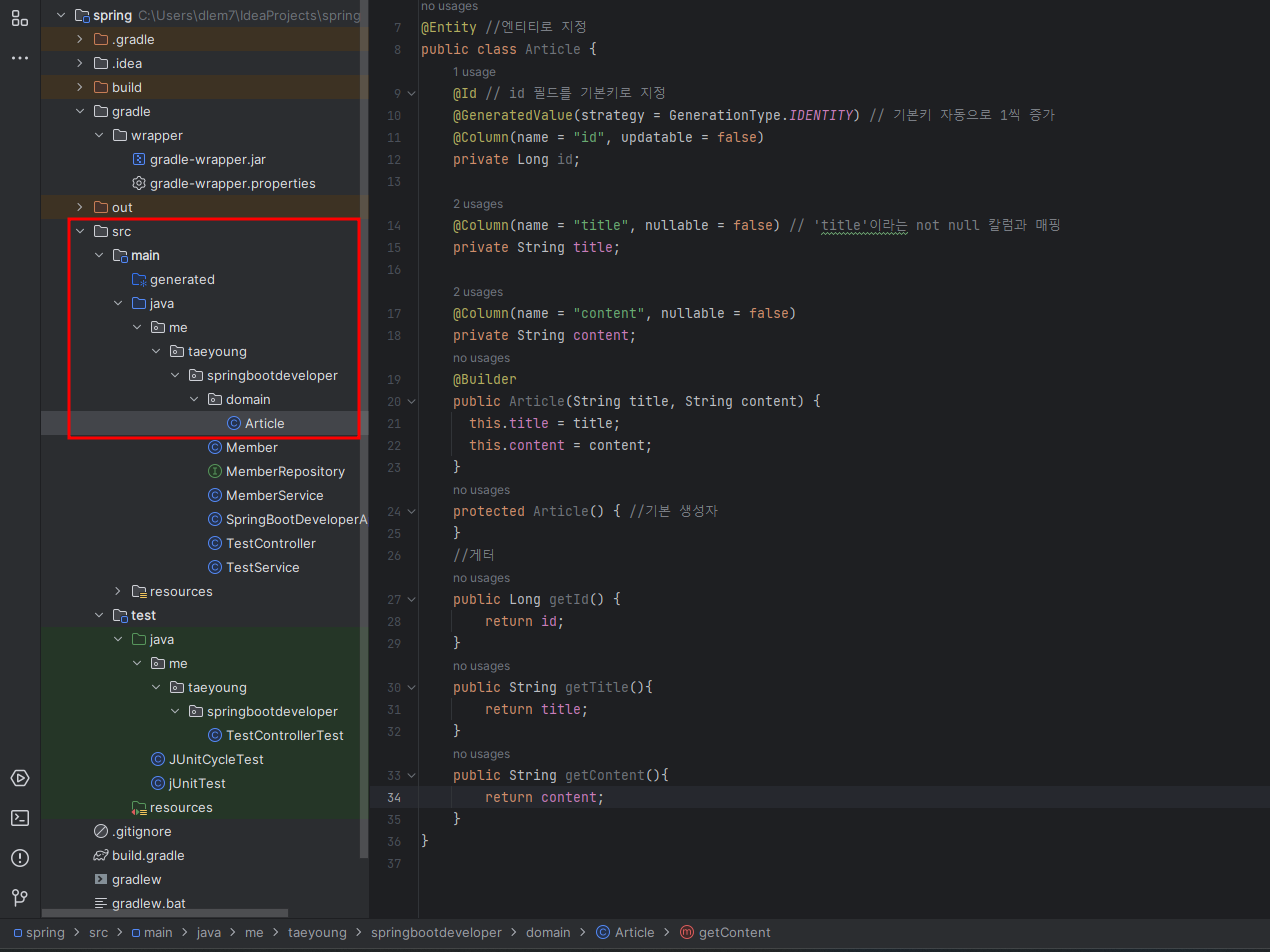
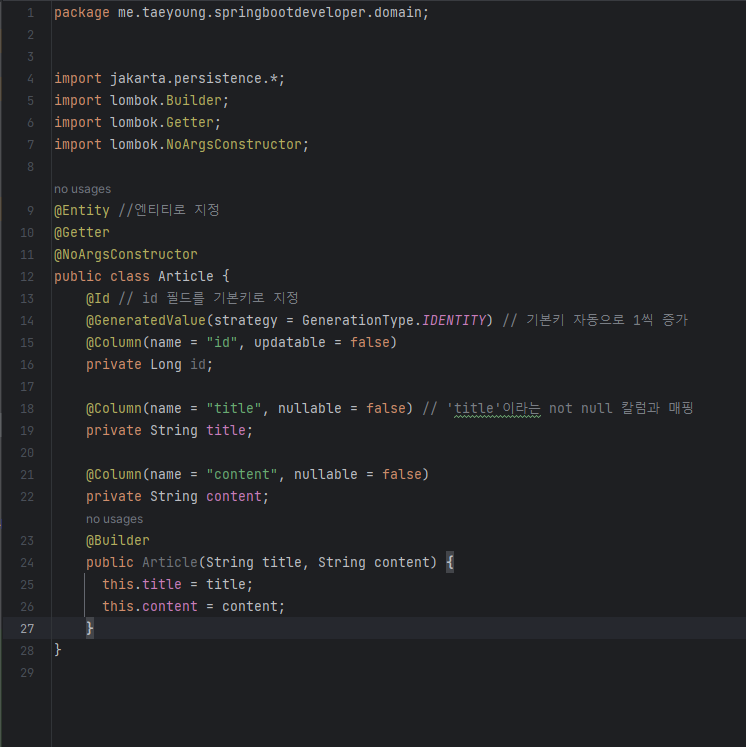
springbootdeveloper 패키지에 domain 패키지를 새로 만들고 domain 패키지에 Article.java파일을 만든 다음, 코드를 작성했다.
@Builder 애너테이션은 롬복에서 지원하는 Annotation인데, 이 Annotation을 생성자 위에 입력하면 빌더 패턴 방식으로 객체를 생성할 수 있어 편리하다.
빌더 패턴을 사용하면 객체를 유연하고 직관적으로 생성할 수 있기 때문에 개발자들이 애용하는 디자인 패턴이다. 즉, 빌더 패턴을 사용하면 어느 필드에 어떤 값이 들어가는지 명시적으로 파악할 수 있다.
다음 코드 예를 보겠다.
// 빌더 패턴을 사용하지 않았을 때
new Article("abc", "def");
//빌더 패턴을 사용했을 때
Article.builder()
.title("abc")
.content("def")
.build();
예를 들어 위에서 작성한 Article 객체를 생성할 때 title에는 abc를, content에는 def값으로 초기화한다고 하겠다.
빌더 패턴을 사용하지 않으면 abc는 어느 필드에 들어가는 값인지, def는 어디 필드에 들어가는 값인지 파악하기가 어렵다. 하지만 빌더 패턴을 사용하면 어느 필드에 어느 값이 매칭되는지 바로 보이므로 객체 생성 코드의 가독성을 높인다. 그리고 @Builder 애너테이션을 사용하면 빌더 패턴을 사용하기 위한 코드를 자동으로 생성하므로 간편하게 빌더 패턴을 사용해 객체를 만들 수 있는 것이다.
이제 위의 코드에 롬복을 사용해서 코드가 더 깔끔하게 바뀌는지 확인해볼 차례다. getId(),getTitle() 같이 필드의 값을 가져오는 게터 메서드들은 public class Article 위에 @Getter 애너테이션, @NoArgsConstructor 애너테이션으로 대치한다. protected Article() {} 코드블록, get 관련 메서드는 모두 삭제하면 된다.
코드를 보면 @NoArgsConstructor 애너테이션을 선언해 접근 제어자가 protected인 기본 생성자를 별도의 코드 없이 생성했고, @Getter 애너테이션으로 클래스 필드에 대해 별도 코드 없이 생성자 메서드를 만들 수 있게 되었다.
이렇게 롬복의 애너테이션을 사용하니까 코드를 반복해 입력할 필요가 없어져서 가독성이 향상 되었다.
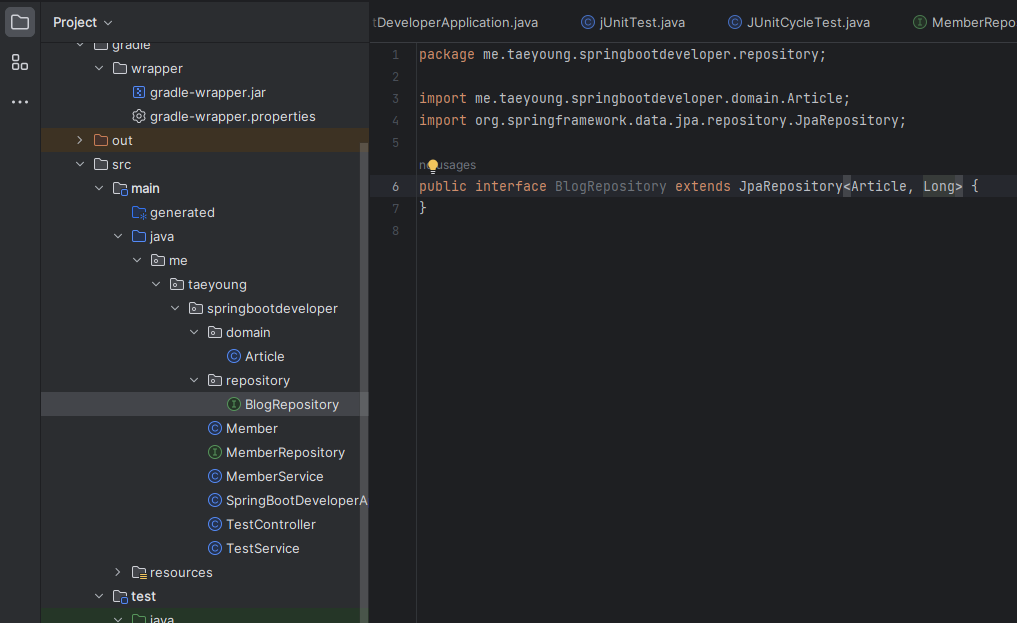
< Repository 만들기 >
springbootdeveloper 패키지에 repository 패키지를 새로 만든 다음, repository 패키지에서 BlogRepository.java 파일을 생성해 BlogRepositoryt 인터페이스를 만들었다.
Reference : Reference : 출처 :스프링 부트 3 백엔드 개발자 되기 - 자바 편
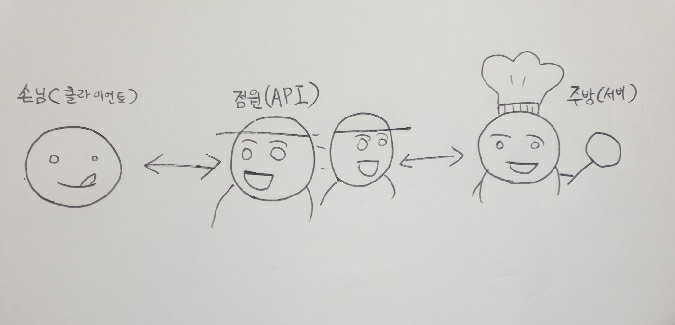
식당에 가면 주방으로 달려가서 요리를 주문하지 않는다. 식당에 들어가면 점원에게 요리를 주문한다. 그리고 점원은 주방에 가서 '요리를 만들어 달라'라고 요청한다. 그리고 요리가 완성되면 점원이 손님에게 요리를 전달한다.
여기서 손님은 클라이언트, 주방에서 일하는 요리사를 서버라고 생각하면 된다. 그리고 중간에 있는 점원을 API라고 생각하면 된다. 이상황을 웹 사이트에 방문하는 상황에 적용해서 생각해보자. 사용자가 주소를 입력해서 '구길 메인 화면을 보여줘'라고 요청을 할 것이다. 그러면 API는 이 요청을 받아 서버에게 가져다준다. 그러면 서버는 API가 준 요청을 처리해 결과물을 만들고 이것을 다시 API로 전달한다. 그러면 API는 최종 결과물을 브라우저에 보내 화면을 볼 수 있게 된다.
이처럼 API는 클라이언트의 요청을 서버에 잘 전달하고, 서버의 결과물을 클라이언트에게 잘 돌려주는 역할을 한다. 그러면 REST API란 무엇일까?
< 웹의 장점을 최대한 활용하는 REST API >
Rest API는 웹의 장점을 극대화하는 인터페이스 설계 방식이다.
REST는 'Representational State Transfer'의 줄임말로, 이는 '자원의 상태를 표현(Represent)하여 주고 받는' 방식을 의미한다. 말하자면, REST API는 자원을 이름으로 구분하고 그 상태로 주고 받는 일관된 인터페이스 설계 방법을 제시한다.
처음 REST API에 대해 들어보면 , 스프링 부트나 리액트, Vue.js와 같은 특정 기술인 줄 착각할 수 있으나. 하지만, REST API는 특정 기술이 아닌 URL 설계 방식을 말한다.
이 REST API의 설계 원칙을 따르면 개발자 입장에서 여러 가지 장점이 있지만, 그와 동시에 몇가지 단점도 존재한다.
< REST API의 특징 >
REST API는 서버/클라이언트 구조, 무상태, 캐시 처리 가능, 계층화, 인터페이스 일관성과 같은 특징이 있다.
< REST API의 장점과 단점 >
REST API의 장점은 URL만 보고도 무슨 행동을 하는 API인지 명확하게 알 수 있다는 것이다.
상태가 없다는 특징이 있어 클라이언트와 서버의 역할이 명확하게 분리된다.
HTTP 표준을 사용하는 모든 플랫폼에서 사용할 수 있다.
REST API의 단점은 HTTP 메서드, 즉, GET,POST와 같은 방식의 개수에 제한이 있고, 설계를 하기 위해 공식적으로 제공되는 표준 규악이 없다.
그럼에도 REST API는 주소와 메서드만 보고 요청의 내용을 파악할 수 있다는 강력한 장점이 있어 많은 개발자들이 사용한다.
심지어 'REST하게 디자인한 API'를 RESTful API라고 부르기도 한다.
< REST API를 사용하는 방법 >
< 규칙 1. URL에는 동사를 쓰지말고, 자원을 표시해야 한다. >
URL은 자원을 표시해야 한다는 말에서 자원은 무엇을 말할까? 자원은 가져오는 데이터를 말한다. 예를 들어 학생 중에 id가 1인 학생의 정보를 가져오는 URL은 이렇게 설계할 수 있다.
/students/1
/get’student?student_id=1
처음에 이 URL을 보면 '어떻게 해도 괜찮은 것 아닐까?'라고 생각할 수 있지만, REST API에 더 맞는, 즉 RESTful API는 1번이다. 왜냐하면 2번의 경우 자원이 아닌 다른 표현을 섞어 사용했기 때문이다. 2번의 경우 동사를 사용해서 추후 개발 시에 혼란을 줄 수 있다. 예를 들어 서버에서 데이터를 요청하는 URL을 설계할 때 어떤 개발자는 get을 어떤 개발자는 show를 쓰면 어떻게 될까? 그러면 URL 구조가 get-student, show-data와 같이 엉망이 될 것이다. 행위는 '데이터를 가져온다'지만 표현이 중구난방이 될테니 말이다. 그래서 RESTful API를 설계할 때는 이러한 동사를 쓰지 않는다.
예문
적합성
설명
/articles/1
적합
동사가 없고, 1번 글을 가져온다는 의미가"명확","적합"
/articles/show/1 /show/articles/1
부적합
show라는 "동사"가 있다. 부적합.
< 규칙 2. 동사는 HTTP 메서드로 >
앞서 동사에 대해서 이야기 했는데, 이건 HTTP 메서드라는 것으로 해결한다. HTTP 메서드는 서버에서 요청을 하는 방법을 나눈 것인데, 주로 사용하는 HTTP 메서드는 POST,GET,PUT,DELETE 이다. 각각 만들고,읽고,업데이트하고,삭제하는 역할을 담당하는데 보통 이것들을 묶어 CRUD라고 부른다. HTTP 메서드의 감을 잡기 위해 블로그에 글을 쓰는 설계를 한다고 생각해보자.
설명
적합한 HTTP 메서드와 URL
id가 1인 블로그 글을 조회하는 API
GET/articles/1
블로그 글을 추가하는 API
POST/articles/1
블로그 글을 수정하는 API
PUT/articles/1
블로그 글을 삭제하는 API
DELETE/articles/1
이외에도 슬래시는 계층 관계를 나타내는데 사용하거나, 밑줄 대신 하이픈을 사용하거나, 자원의 종류가 컬렉션인지 도큐먼트인지 따라 단수, 복수를 나누거나 하는 등의 규칙이 있다.
스프링 데이터는 비즈니스 로직에 초점을 맞출 수 있도록 데이터베이스 사용 기능을 클래스 레벨에서 추상화한다. 이를 위해 제공하는 여러 인터페이스를 통해 스프링 데이터를 활용할 수 있다. 이들 인터페이스는 CRUD와 같은 다양한 메서드를 포함하며, 이를 사용하면 스프링 데이터가 자동으로 쿼리를 생성해준다.
추가적으로, 스프링 데이터는 페이징 처리 기능이나 메서드 이름으로 자동 쿼리 빌딩 등 다양한 기능을 제공한다. 그리고 각 데이터 베이스의 특성에 맞춰 확장 기능을 제공한다. 예를 들자면, JPA(Java Persistence API) 표준 스펙은 스프링 데이터 JPA를, MongoDB는 스프링 데이터 MongoDB를 사용할 수 있다.
🤔< 스프링 데이터 JPA란? > 🤔
스프링 데이터 JPA는 스프링 데이터의 일반적인 기능에 JPA 특화 기능이 추가된 라이브러리이다. 여기서 제공하는 JpaRepository 인터페이스는 스프링 데이터의 PagingAndSortingRepository 인터페이스를 상속받아 만들어졌으며,
JPA를 좀 더 간편하게 사용할 수 있는 메서드를 제공한다.
예를 들어, 스프링 데이터 JPA를 사용하지 않고, 엔티티의 상태를 바꾸려면 다음과 같이 작업을 해야 한다.
@PersistenceContext
EntityManager em;
public void join() {
// 기존에 인티티 상태를 바꾸는 방법(메서드 호출을 해서 상태 변경)
Member member = new Member(1L, "홍길동");
em.persist(member);
}
하지만 스프링 데이터 JPA를 사용하면, 데이터베이스의 CRUD 작업을 간편하게 처리할 수 있다. 다음과 같이 JpaRepository 인터페이스를 상속받은 사용자 정의 인터페이스를 만들고, 제네릭에는 <관리할 엔티티 이름, 엔티티 기본키 타입>을 입력하면, 기본적으로 제공되는 CRUD 메서드를 사용할 수 있다.
public interface MemberRepository extends JpaRepository<Member, Long> {
}
🐻❄️< 스프링 데이터 JPA에서 제공하는 메서드 사용해보기 > 🐻❄️
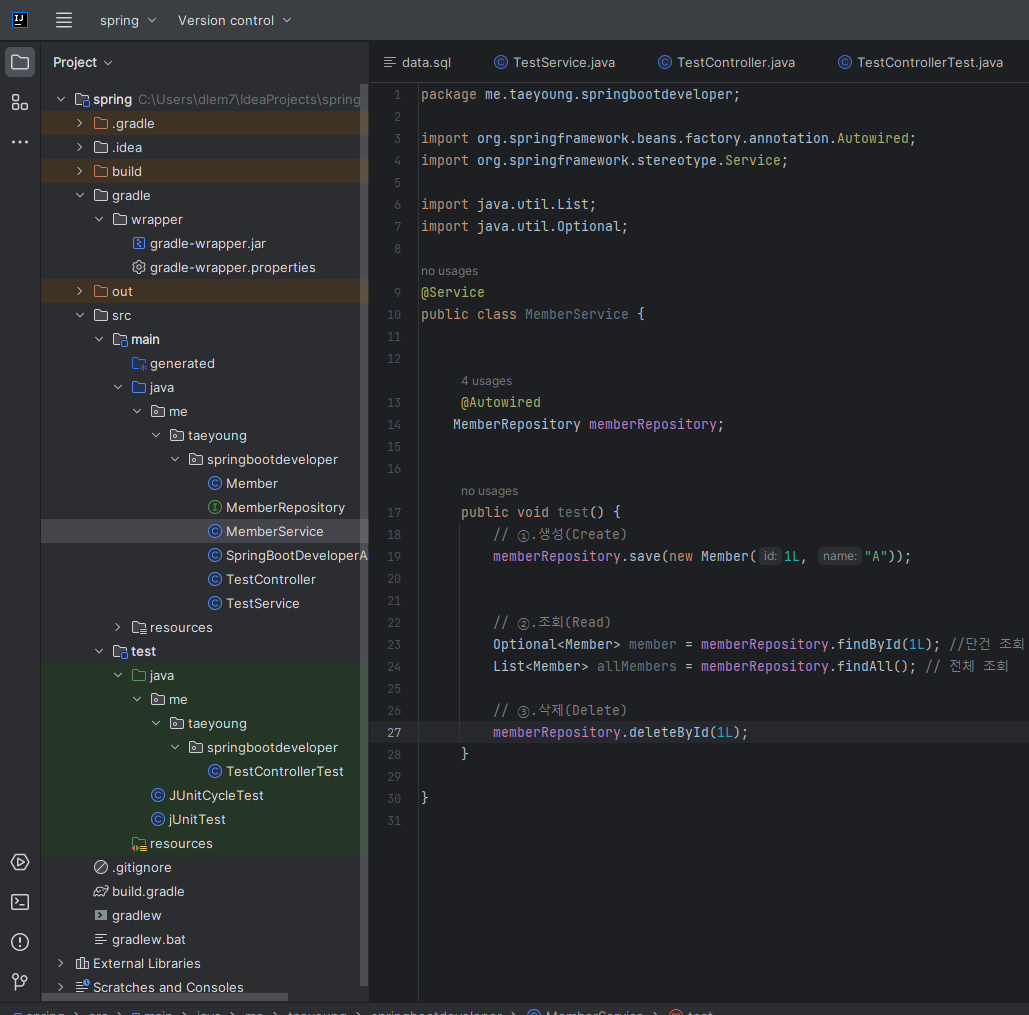
1.src/main/java/me/taeyoung/springbootdeveloper 경로에 MemberService.java를 생성해 코드를 아래와 같이 작성했다.
① save() 메서드를 호출해 데이터 객체를 저장할 수 있다. 전달 인수로 엔티티 Member를 넘기면 반환값으로 저장한 엔티티를 반환받을 수 있다.
②.findById() 메서드에 id를 지정해 엔티티를 하나 조회할 수 있다. findAll()메서드는 전체 엔티티를 조회한다.
③.deleteById()메서드에 id를 지정하면 엔티티를 삭제할 수 있다.
< 예제 코드 살펴보기 >
지금까지 많은 Annotation을 사용했다. 이제 Annotation이 어떤 역할을 하는지 알아볼 차례이다.
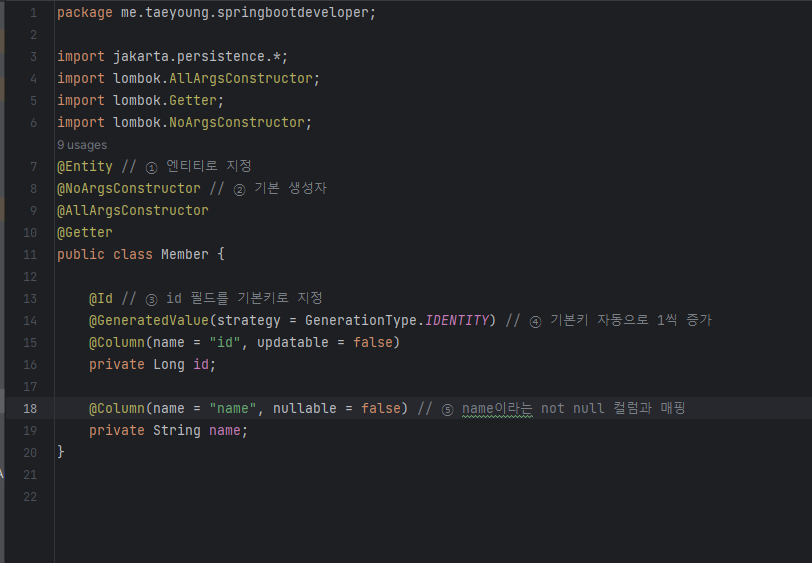
[Member.java]
①. @Entity Annotation은 Member 객체를 JPA가 관리하는 엔티티로 지정한다. 즉, Member 클래스와 실제 데이터베이스의 테이블을 매핑시킨다. @Entity의 속성 중에 name을 사용하면 name의 값을 가진 테이블 이름과 매핑되고 테이블 이름을 지정하지 않으면 클래스 이름과 같은 이름의 테이블과 매핑이 된다. 여기서는 테이블 이름을 지정하지 않았으므로 클래스 이름과 같은 데이터베이스의 테이블인 member 테이블과 매핑된다. @Entity Annotation에서 테이블을 지정하고 싶다면 다음과 같이 name 파라미터에 값을 지정해주자.
② protected 기본 생성자이다. 엔티티는 반드시 기본 생성자가 있어야 하고, 접근 제어자는 public 또는 protected 이어야 한다. public보다는 protected가 더 안전하므로 접근 제어자가 protected인 기본 생성자를 생성한다.
③ @Id는 Long 타입의 id 필드를 테이블의 기본키로 지정한다.
④ @GeneratedValue는 기본키의 생성 방식을 결정한다. 여기서는 자동으로 기본키가 증가하도록 지정했다.
여기서는 IDENTITY라는걸 사용 했는데, 다양한 자동키 생성 설정 방식이 있다.
Auto :선택한 데이터베이스 방언에 따라 방식을 자동으로 선택(기본값)
IDENTITY : 기본 키 생성을 데이터베이스에 위임(= AUTO_INCREMENT)
SEQUNCE : 데이터 베이스 시퀀스를 사용해 기본 키를 할당하는 방법. 오라클에서 주로 사용
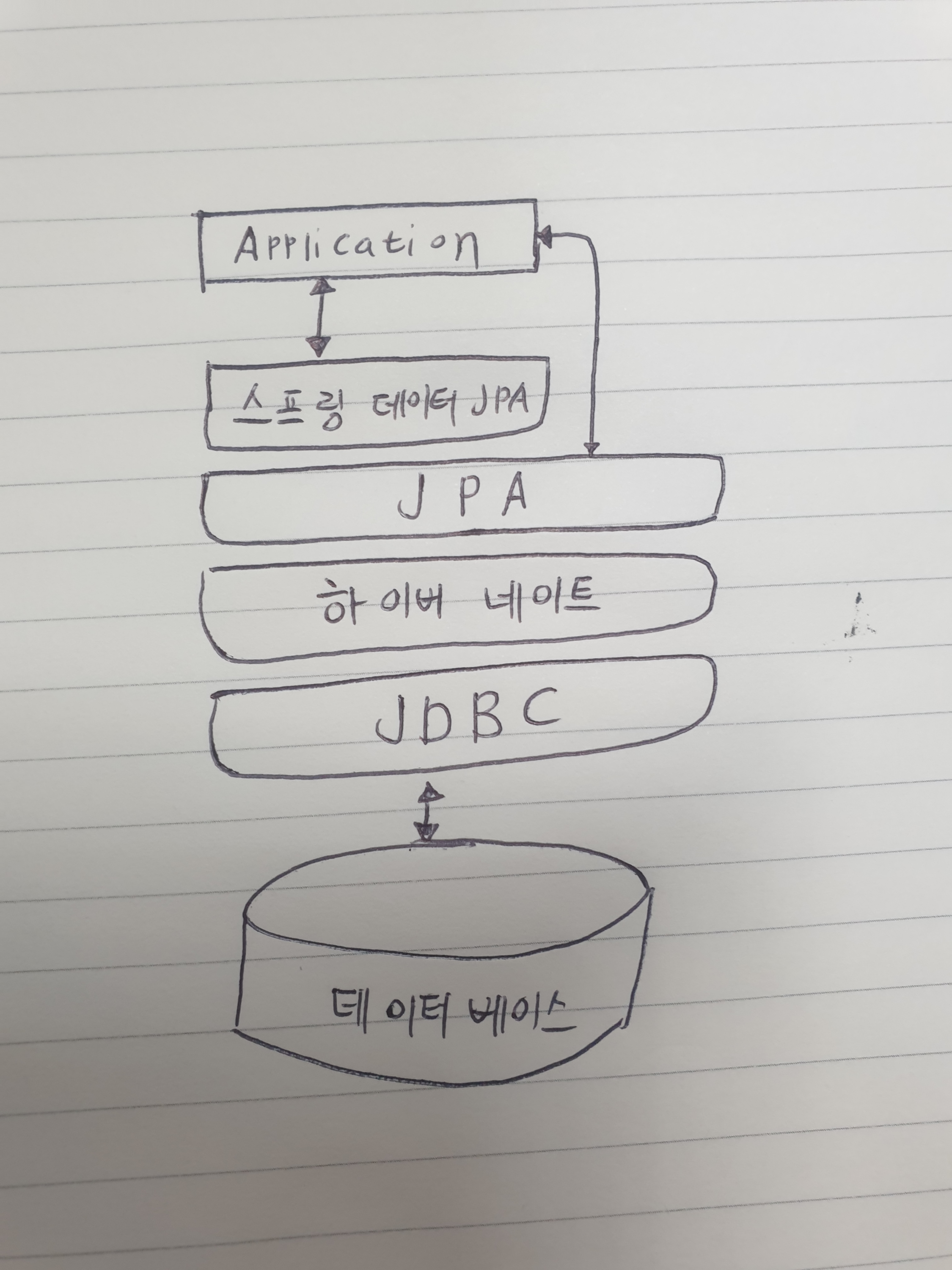
ORM이란, Object-Relational Mapping의 약자로, 객체 지향 프로그래밍 언어를 사용하여 호환되지 않는 유형 시스템 간에 데이터를 변환하는 프로그래밍 기법을 말한다. 즉, 프로그래밍 언어의 객체와 데이터베이스의 데이터를 자동으로 연결해주는 역할을 한다. < JPA란? > Java에서는 JPA(Java Persistence API)를 ORM 표준으로 사용하며. JPA는 자바에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스이다. 이 JPA를 사용하면 개발자는 데이터베이스의 데이터를 마치 자바의 객체처럼 쉽게 다룰 수 있게 된다.
하지만JPA는 인터페이스이므로 실제 동작을 위해서는 이를 구현한 ORM 프레임워크를 추가로 선택해야 한다.
< Hibernate란 ? >
ORM 프레임워크 중 하나인 Hibernate는 JPA 인터페이스를 구현한 구현체이자 자바용 ORM 프레임워크이다. 이는 내부적으로 JDBC API를 사용하며, Hibernate를 통해 개발자는 직접적인 SQL 쿼리문 없이도 데이터베이스와의 작업을 수행할 수 있다.
Hibernate의 가장 큰 장점은 데이터베이스의 종류에 상관없이 일관된 코드로 데이터베이스 작업을 처리할 수 있다는 점이다. 즉, MySQL, Oracle, PostgreSQL 등 어떤 데이터베이스를 사용하더라도, Hibernate를 통한 코드 작성 방식은 동일하다.
< 엔티티 매니저란? >
<엔티티>
엔티티(Entity)는 기본적으로 자바 객체이다. 하지만 이는 일반적으로 자바 객체와는 조금 특별한 성질을 가지고 있다.
바로 "데이터베이스 테이블과 매핑" 된다는 특성이다.
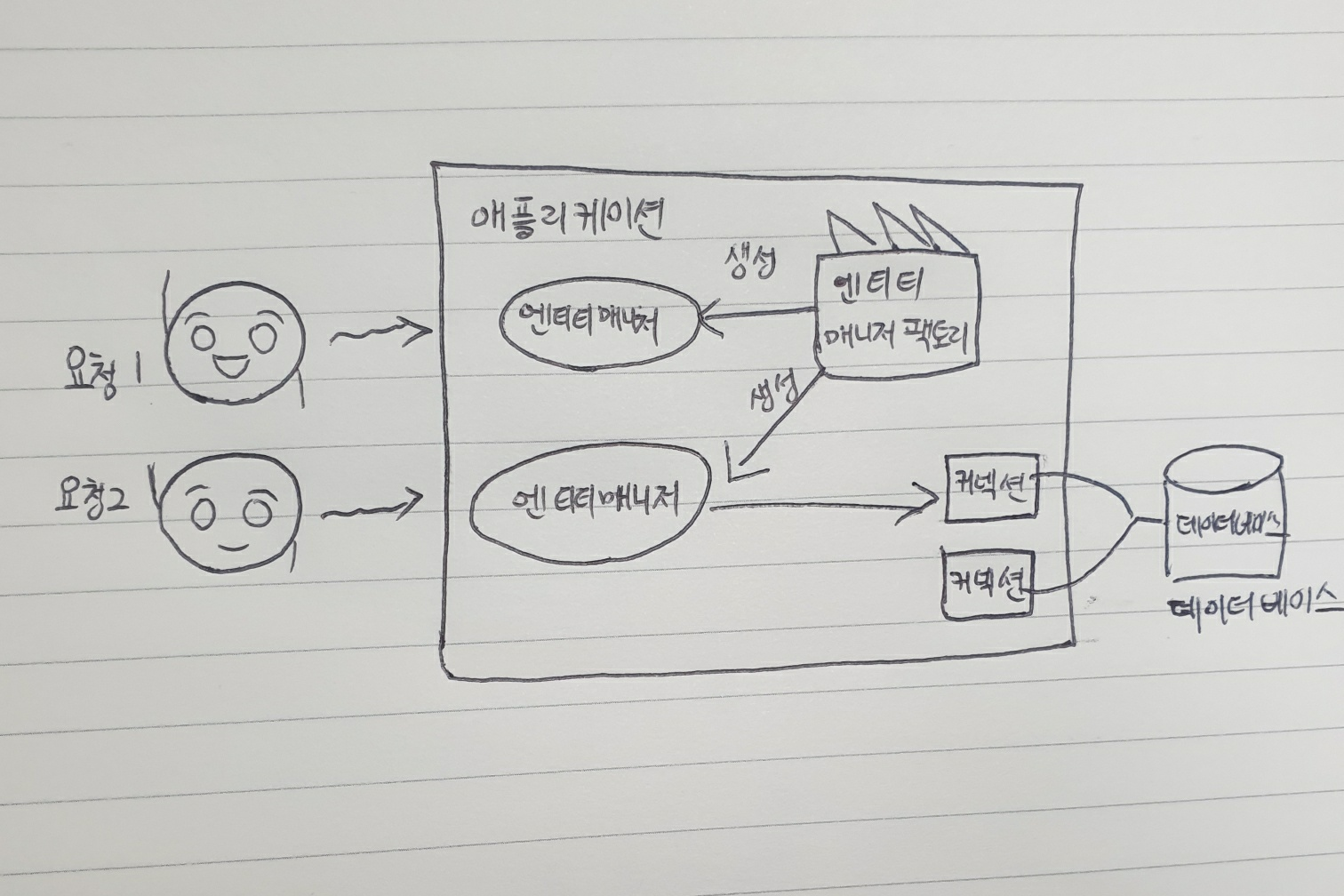
<엔티티 매니저>
엔티티 매니저(entity manager)는 엔티티의 생성,수정,삭제 등의 작업을 수행한다. 이러한 엔티티 매니저는 '엔티티 매니저 팩토리(Entity Manager Factory)'에서 만들어진다.
예를 들어, 두 명의 사용자가 동시에 회원 가입을 한다고 생각해보자. 이때 각 사용자의 회원 가입 요청에 대해 엔티티 매니저 팩토리는 독립적인 엔티티 매니저를 생성한다. 각 엔티티 매니저는 자신이 담당하는 사용자의 정보를 데이터베이스에 저장하게 된다. 이렇게 각각의 엔티티 매니저를 통해 회원 가입 처리가 완료되면, 사용자 정보는 데이터베이스에 안전하게 저장된다.
스프링 부트에서는 직접 엔티티 매니저 팩토리를 생성,관리하지 않는다. 스프링 부트는 내부적으로 엔티티 매니저 팩토리를 하나만 생성하고 이를 공유한다. 이런 점이 바로 스프링 부트가 간편함과 효율성을 제공하는 비결 중 하나이다.
< Spring boot가 엔티티 매니저를 사용하는 방법 예시 >
스프링 부트에서는 @PersistenceContext 또는 @Autowired 어노테이션을 사용해서 엔티티 매니저를 사용한다.
이 Annotation을 사용하면 Spring boot가 관리하는 엔티티 매니저를 손쉽게 사용할 수 있다.
@PersistenceContext
EntityManager em; // 프록시 엔티티 매니저. 필요할 때 진짜 엔티티 매니저 호출
여기서 중요한 점은 스프링 부트는 기본적으로 빈은 하나만 생성하여 공유한다는 점이다. 따라서 동시성 문제가 발생할 수 있다. 이 문제를 해결하기 위해 스프링 부트는 '프록시 엔티티 매니저'를 사용한다. 이는 실제 엔티티 매니저와 연결하는 가짜 엔티티 매니저로, 필요할 때 데이터베이스 트랜잭션과 관련된 실제 엔티티 매니저를 호출한다.
영속성컨텍스는 JPA의 가장 중요한 개념 중 하나로, 단순히 이해 하자면 엔티티를 저장하고 관리하는 가상의 데이터베이스 공간이라고 볼 수 있다. 엔티티 매니저는 이 영속성 컨텍스트를 통해 엔티티를 관리하며, 데이터베이스와의 상호작용을 효과적으로 수행한다.
< 영속성 컨텍스트의 핵심 특징 >
1차 캐시
영속성 컨텍스트는 내부에 1차 캐시라는 메모리 공간을 가지고 있다. 이 곳에는 데이터베이스에서 조회한 엔티티가 저장되면서, 이후 같은 엔티티를 조회하려 할 때 이 캐시를 먼저 확인하여 데이터베이스 접근을 줄이는 역할을 한다. 이렇게 함으로써 데이터 조회 속도를 크게 향상 시킬 수 있다.
쓰기 지연
쓰기 지연(transactional write-behind)는 엔티티에 대한 변경(추가,수정,삭제)이 일어났을 때, 즉시 데이터베이스에 반영하는 것이 아니라, 트랜잭션을 커밋하는 시점에 한꺼번에 반영하는 기능이다. 이를 통해 데이터베이스의 부담을 줄이면서, 성능을 향상시킬 수 있다.
변경 감지
영속성 컨텍스트는 트랜잭션 커밋 시점에 1차 캐시에 저장된 엔티티와 현재 엔티티의 상태를 비교한다. 이를 통해 변경된 내용이 있는지를 자동으로 감지하고, 이를 데이터베이스에 반영한다.
지연 로딩
지연 로딩(lazy loading)은 엔티티가 실제로 사용되는 시점에서 데이터베이스에서 데이터를 로딩하는 기능이다. 이를 통해 불필요한 데이터 로딩을 최소화하여 애플리케이션의 성능을 향상시킬 수 있다.
< 엔티티의 상태 >
엔티티는 4가지의 상태를 가진다. 영속성 컨텍스트가 관리하고 있지 않는 분리(detached)상태, 영속성 컨텍스트가 관리하는 관리(managed)상태, 영속성 컨텍스트와 전혀 관계가 없는 비영속(transient)상태, 삭제된(removed)상태로 나뉜다.
이 상태는 특정 메서드를 호출해 변경할 수 있는데, 필요에 따라 엔터티의 상태를 조절해 데이터를 올바르게 유지하고 관리할 수 있다.
< 엔티티의 상태 변경 예시 코드 >
public class EntityManagerTest {
@Autowired
EntityManager em;
public void example() {
// 1. 엔티티 매니저가 엔티티를 관리하지 않는 상태(비영속 상태)
Member member = new MEmber(1L, "홍길동");
// 2. 엔티티가 관리 상태가 된다.(관리 상태)
em.persist(member);
// 3. 엔티티 객체가 분리된 상태가 된다.(분리 상태)
em.detach(member);
// 4. 엔티티 객체가 삭제된 상태가 된다.(삭제 상태)
em.remove(member);
}
}
1.엔티티를 처음 만들면 엔티티는 비영속 상태가 된다.
2.persist() 메서드를 사용해 엔티티를 관리 상태로 만들 수 있으며, Member 객체는 영속성 컨텍스트에서 상태가 관리 된다.
3.만약 엔티티를 영속성 컨텍스트에서 관리하고 싶지 않다면 detach()메서드를 사용해 분리 상태로 만들 수 있다.
4. 또한 더 이상 객체가 필요 없다면 remove()메서드를 사용해서 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제할 수 있다.
Reference : Reference : 출처 :스프링 부트 3 백엔드 개발자 되기 - 자바 편
데이터베이스는 효율적으로 데이터를 저장하고 검색할 수 있는 시스템이다. 데이터베이스의 주요 이점은 많은 사용자가 데이터를 안전하게 활용하고,관리 할 수 있다는 것이다.
💻<데이터베이스 관리자, DBMS>💻
데이터베이스를 효율적으로 관리하고 운영하기 위한 소프트웨어를 DBMS(database management system)이라고 한다.
DBMS의 역할은 여러 사용자가 동시에 데이터베이스에 접근하고 사용할 수 있도록 하는 것이며, 이를 통해 데이터의 공유가 가능하다. 또한, DBMS는 다양한 요구사항을 만족시키면서도 데이터베이스를 효율적으로 관리해야한다.
그래서 일반적으로 사람들이 '데이터베이스'라고 부르는 MYSQL이나 Oracle 같은 것들은 실제로는 DBMS인 것이다. 이들은 데이터를 관리하는 방식에 따라서 관계형,객체-관계형,문서형,비관계형 등 다양한 유형으로 나뉠 수 있다. 이중에서 가장 널리 사용되는 유형은 관계형 DBMS이다.
📀<관계형 DBMS>📀
RDBMS라고 부른다. 관계형이라는 말을 쓰는 이유는 이 DBMS가 관계형 모델을 기반으로 하기 때문이다. RDBMS는 어렵게 생각할 필요 없이 테이블 형태로 이루어진 데이터 저장소를 생각하면 된다. 예를 들어 회원 테이블이 있다고 가정하면 각 행은 고유의 키,즉, 아이디를 가지고 있고, 이메일,나이와 같은 회원과 관련된 값들이 들어간다.
회원테이블
ID
이메일
나이
1
Yoontaeyoung@test.com
10
2
Yoontaeyoung123@test.com
20
3
Yoontaeyoung987@test.com
30
이때 데이터 1, Yoontaeyoung@test.com,10 한 줄을 행이라고 하고, ID,이메일,나이와 같은 구분을 열이라고 한다.
⚡< 데이터베이스를 시작하기전 "꼭" 알아둬야할 데이터베이스 용어 >⚡
<테이블>
테이블은 데이터베이스에서 데이터를 정리하고 구성하는데 사용되는 핵심적 구조이다. 행(row)와 열(column)의 형태로 구성되며, 각 행은 다양한 속성을 나타내는 데이터들로 이루어져 있다.
<행>
행(row)은 테이블의 구성 요소 중 하나이며 테이블의 가로로 배열된 데이터의 집합을 의미한다. 예를 들어 회원 테이블이 있다고 할 때 ID가 1번인 회원의 이메일,나이 같은 정보가 모여있는 집합이 1번 회원에 대한 행이라고 할 수 있다. 행은 반드시 고유한 식별자인 기본 키를 가진다. 행을 레코드(recode)라고 부르기도 한다.
<열>
열(column)은 테이블의 구성 요소 중 하나로, 특정 데이터 유형이 저장된다. 예를 들어, 회원 정보 테이블에서 '이메일'과 '나이'는 각각의 열이 될 수 있으며, 이 열들은 데이터의 무결성을 보장한다. 즉, 각 열은 해당하는 데이터 유형만을 저장한다.
<기본키>
기본키(primary key)는 행을 구분할 수 있는 식별자이다. 이 값은 테이블에서 유일해야 하며, 중복 값을 가질 수 없다. 보통 데이터를 수정하거 삭제하고, 조회할 때 사용되며 다른 테이블과 관계를 맺어 데이터를 가져올 수도 있다. 또한 기본키의 값은 수정되어서는 안 되며 유효한 값이어야 한다. 즉 NULL이 될 수 없다.
<쿼리>
쿼리(query)는 데이터베이스에서 데이터를 조회하거나 삭제,생성,수정 같은 처리를 하기 위해 사용 하는 명령문이다. SQL이라는 데이터베이스 전용 언어를 사용하여 작성한다.
🔥< ORM이란? >🔥
ORM(Object-relational mapping)은 데이터베이스와 프로그래밍 언어 사이의 '다리'역할을 한다. 데이터베이스에 저장된 정보를 프로그래밍 언어가 이해할 수 있는 형태, 즉'객체'로 변환해주는 기법이다.
그럼 ORM이 왜 필요한지 예를 들어 설명해보자. 데이터베이스에 '홍길동'이라는 이름과 '20'이라는 나이가 저장되어 있다고 가정해보자. 이 정보를 자바 같은 프로그래밍 언어로 활용하려면 일반적으로 SQL이라는 데이터베이스 전용 언어를 사용해야 한다. 하지만 ORM이 있으면, 별도로 SQL을 배우지 않아도 이 정보를 자바 객체로 바로 사용할 수 있다.
즉, ORM은 프로그래밍 언어로 데이터베이스를 손쉽게 다룰 수 있게 해주는 도구라고 볼 수 있다. 이런 ORM 활용에는 ㄷ장단점이 있다.
< 장점 >
ⓐ.SQL을 몰라도 프로그래밍 언어로 데이터를 다룰 수 있다.
ⓑ.코드를 객체지향적으로 작성할 수 있어 비즈니스 로직에 더 집중할 수 있다.
ⓒ.데이터베이스 시스템을 쉽게 변경할 수 있다. (예:MySQL에서 PostgreSQL로)
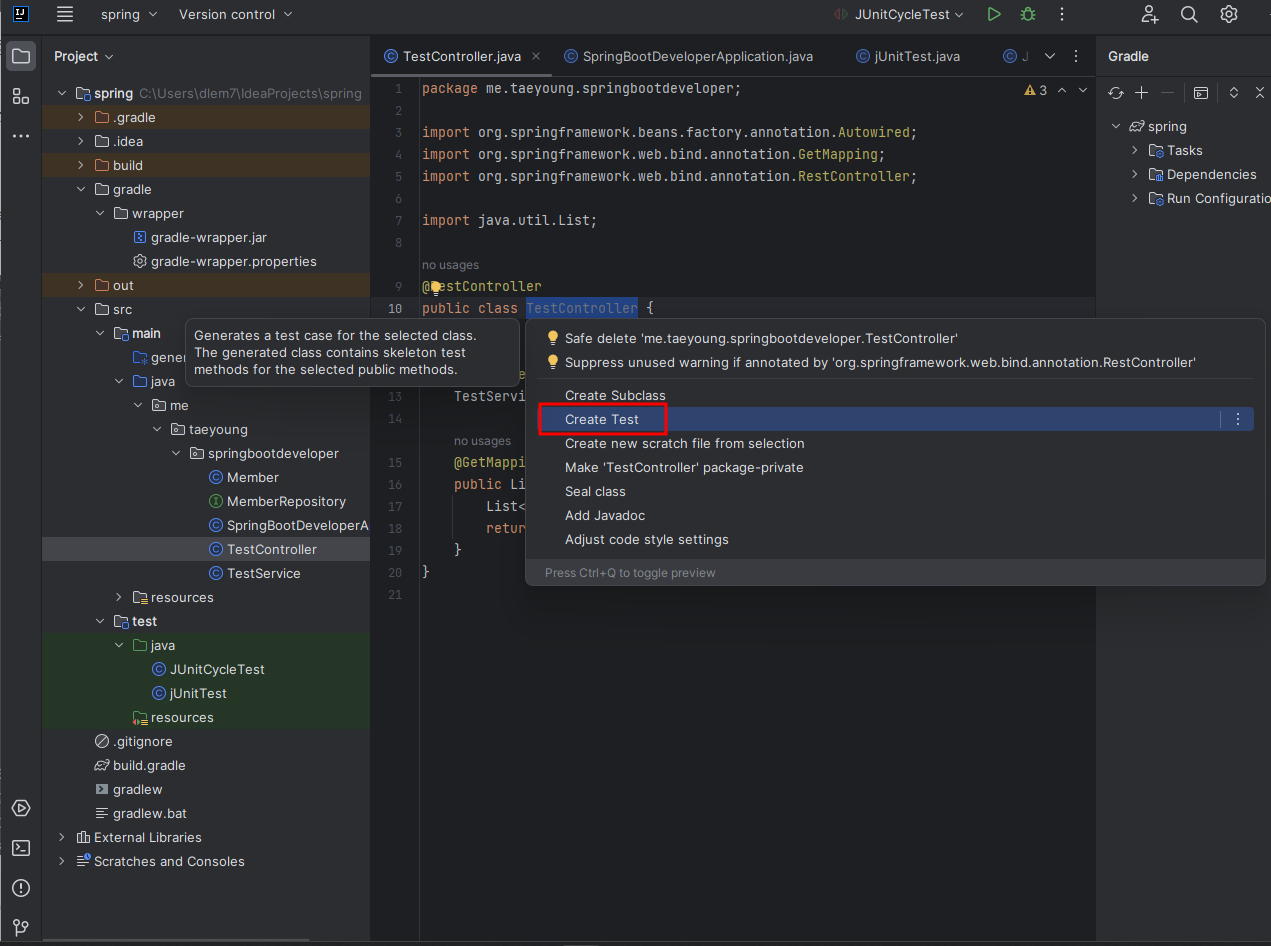
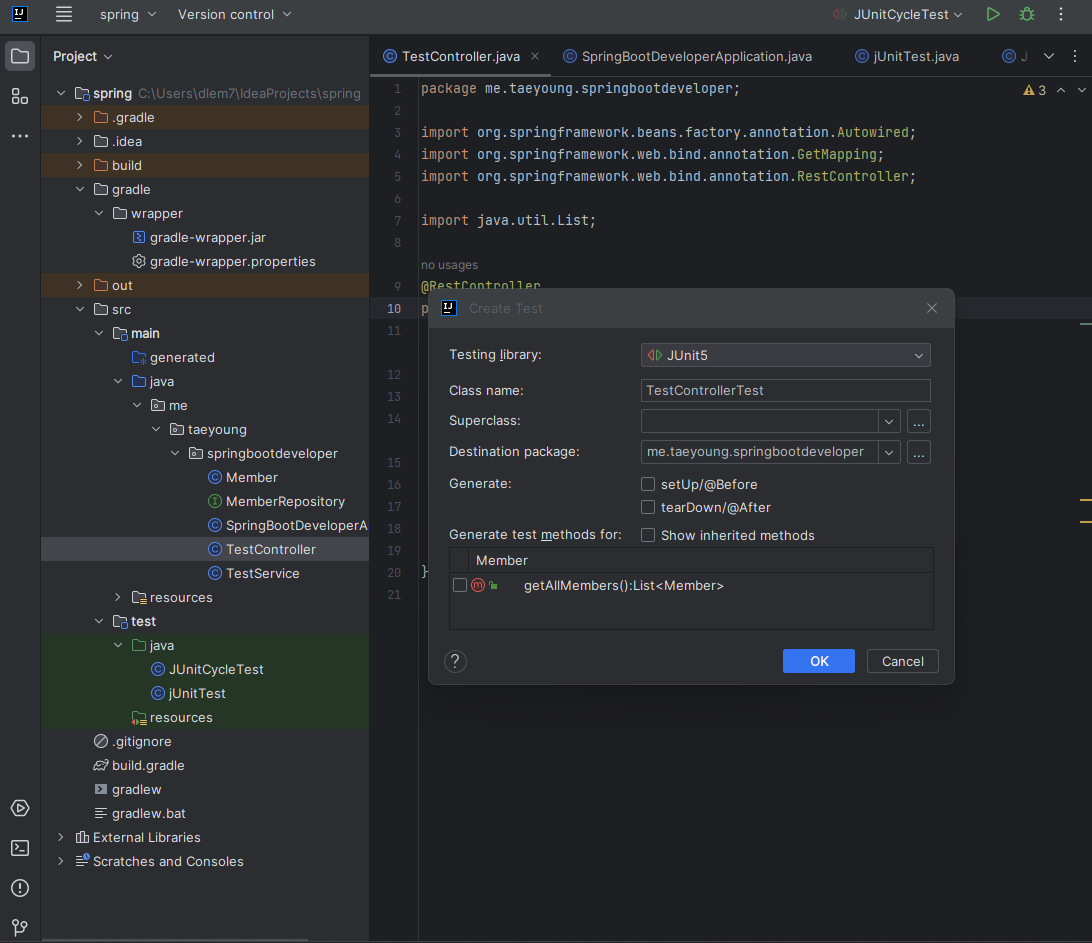
TestController.java 파일을 열고 클래스 이름 위에 마우스 커서를 놓고 클릭한 다음 Alt + Enter 을 누르면 [Create Test] 가 나타난다.
위의 Create Test를 누르면 아래와 같은 창이 나타난다.
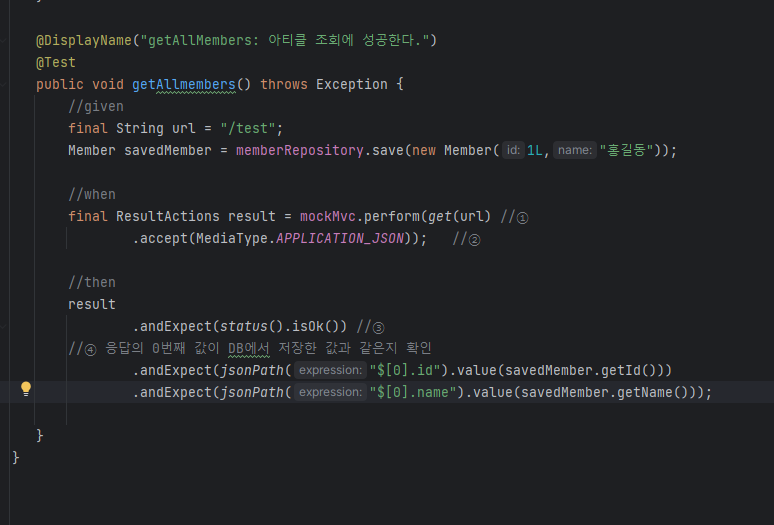
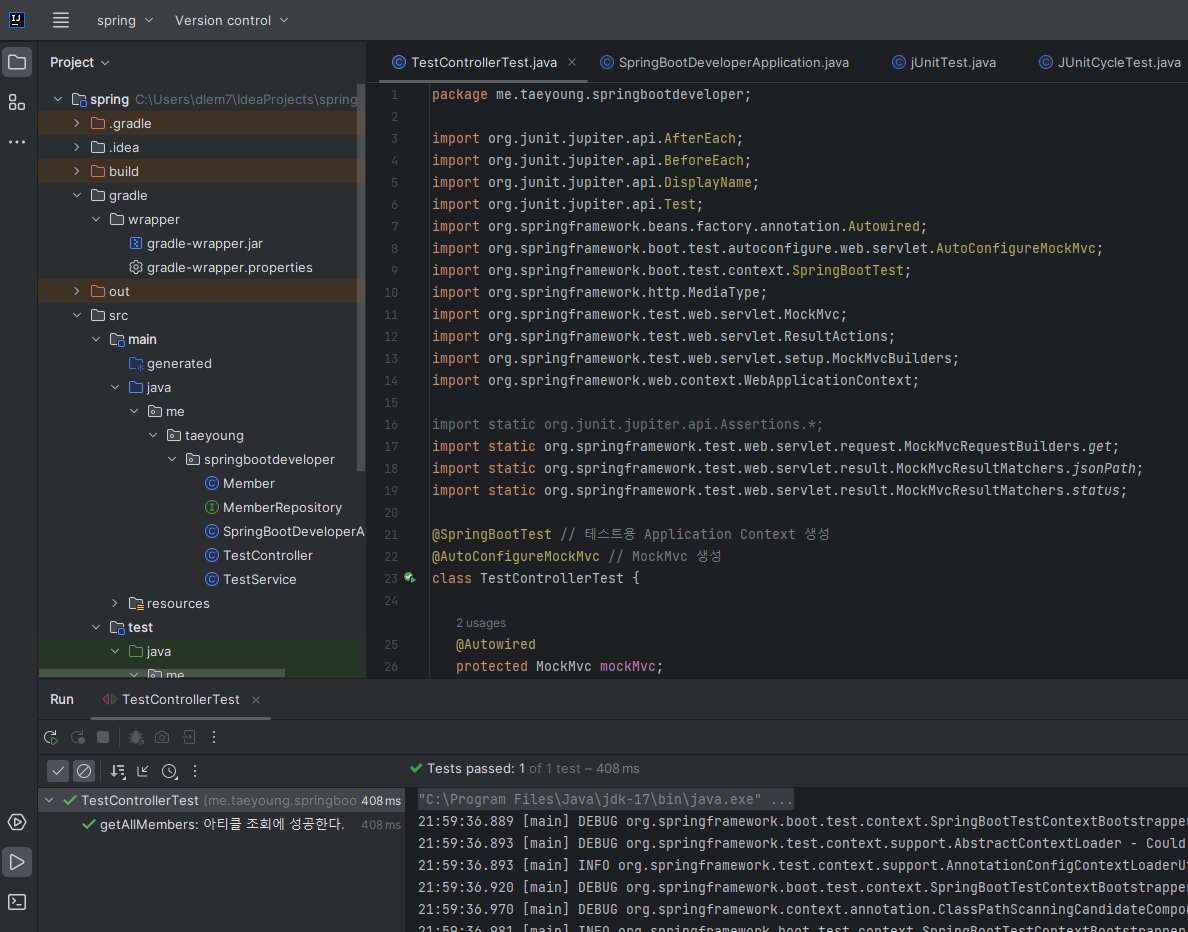
OK를 누르면 TestControllerTest.java 파일이 test/java/패키지 아래에 생성된다. 생성된 파일을 다음과 같이 작성한다. 여기서는 테스트 코드를 작성하기 위해 또 새로운 Annotation을 사용했다.
🚀 < 위의 코드에서 꼭 알아둬야 할 Annotation > 🚀
<@SpringBootTest>
@SpringBootTest Annotation은 Main Application class에 추가하는 Annotation인 @SpringBootApplication이 있는 Class를 찾고, 그 Class에 포함되어 있는 Bean을 찾은 다음에 Test용 "Aplication Context"라는 것을 만든다.
<@AutoConfigureMockMvc>
@AutoConfigureMockMvc는 MockMvc를 생성하고 자동으로 구성하는 Annotation이다. MockMvc는 Aplication을 서버에 배포하지 않고도 Test용 MVC환경을 만들어 요청 및 전송, 응답 기능을 제공하는 유틸리티 클래스다. 즉, 컨트롤러를 테스트 할 때 사용되는 클래스다.
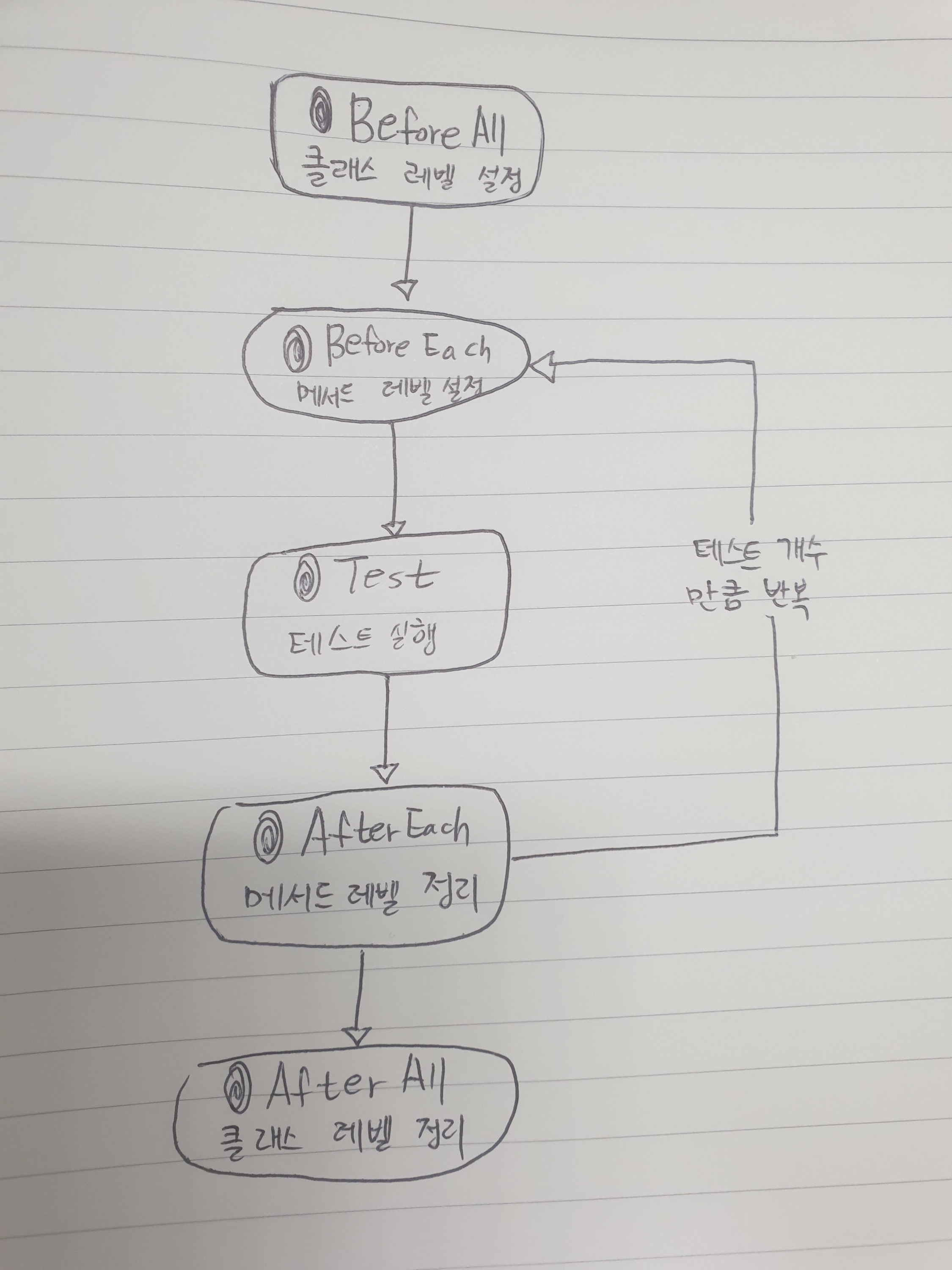
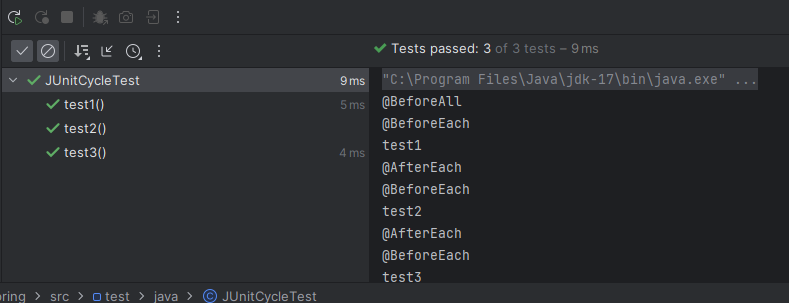
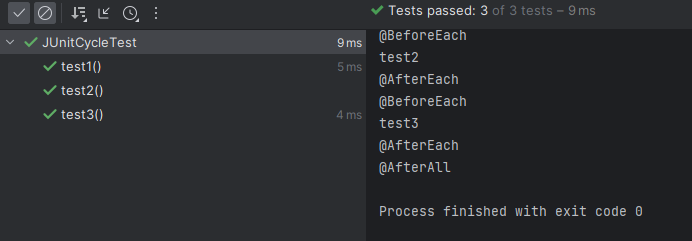
<@BeforeEach>
테스트를 실행하기 전에 실행하는 메서드에 적용하는 Annotation. 여기서는 MockMvcSetUp() 메서드를 실행해 MockMvc를 설정해준다.
<@AfterEach>
테스트를 실행한 이후에 실행하는 메서드에 적용하는 Annotation. 여기서는 cleanUp() 메서드를 실행해 member 테이블에 있는 데이터들을 모두 삭제해준다.