①. 그림을 보면 Postman에서 Tomcat에 /test GET Request를 보낸다. 그러면 이 Request는 Spring Boot 내로 이동하게 된다.
②.이때 Spring Boot의 Dispatcher servlet이 URL을 분석 후, 이 Request를 처리할 수 있는 Controller를 찾는다.
TestController가 /test라는 패스에 대한 GET 요청을 처리할 수 있는 getAllMembers() Method를 가지고 있다는 가정하에 Dispatcher servlet은 TestController에게 /test GET Request를 전달한다.
③.마침내 /test GET Request를 처리할 수 있는 getAllMembers() Method와 이 요청이 매치된다. 그리고 getAllMembers() method에서는 Business 계층과 Persistence Layer를 통하여 필요한 Data를 가져온다.
④.그러면 View Resolver가 Template Engine을 통해 HTML Doc을 만들거나, JSON,XML 등의 Data를 생성한다.
⑤.그 결과 members를 return하고 그 Data를 Postman에서 볼 수 있게 된다.
Spring Boot는 다음 그림에서 보듯 각 계층이 양 옆의 계층과 통신하는 구조를 따른다. 여기서 계층이라는 단어는
각자의 역할,책임이 있는 어떤 Software의 구성 요소를 의미한다. 각 계층은 서로 소통할 수는 있으나 다른 계층에 직접 간섭하거나 영향을 미치지는 않는다.
<🍗치킨과 🍕피자로 이해하는 계층 >
어떤 거리에 치킨집과 피자집이 있다고 생각해보자. 치킨은 치킨을, 피자는 피자를 판다.
그런데 필요한 경우 협업 관계를 맺음으로 어떤 손님이 피자를 사면 치킨을 할인 할 수도 있다.
이것이 계층 간의 소통이다. 하지만 치킨 알바생이 치킨을 팔다 말고 피자집에 가서 피자를 팔 수는 없는 것이다.
즉, 계층은 서로 영향을 끼치지는 못한다. 이렇게 각 계층은 자신의 책임에 맞는 역할(치킨 팔기,피자 팔기)를 수행하며,
필요에 따라 소통(피자 사면 치킨 할인)한다. Spring boot에는 presentation,Business,Persistence 계층이 있다. 이 계층이 서로 통신하며 프로그램을 구성 한다.
🌈 Presentation 계층 (Controller)
Presentation 계층은 사용자로부터 요청을 받아들이고, 사용자에게 응답을 전달하는 역할을 한다. 이는 웹 어플리케이션의 '얼굴'이라고 볼 수 있으며, 이 계층에서는 사용자의 요청을 파싱하고 유효성을 검사한 후에 적절한 Business 계층의 메서드를 호출한다. Spring Boot에서는 @Controller 또는 @RestController 어노테이션이 붙은 클래스가 이 역할을 담당한다.
🌈Business 계층 (Service)
Business 계층은 실제 비즈니스 로직이 구현되는 곳으로, Presentation 계층에서 받은 요청을 처리하고 결과를 반환한다. 예를 들어, 온라인 상점에서 주문이 들어왔을 때 주문 처리 로직, 재고 확인, 할인 적용 등의 비즈니스 로직이 이 계층에서 구현된다. Spring Boot에서는 @Service 어노테이션이 붙은 클래스가 이 역할을 담당한다.
🌈Persistence 계층 (Repository)
Persistence 계층은 데이터에 직접 접근하는 역할을 한다. 주로 데이터베이스와의 상호작용을 처리하며, 데이터를 생성(Create), 읽음(Read), 업데이트(Update), 삭제(Delete)하는 CRUD 연산을 담당한다. Spring Boot에서는 @Repository 어노테이션이 붙은 클래스가 이 역할을 담당한다..
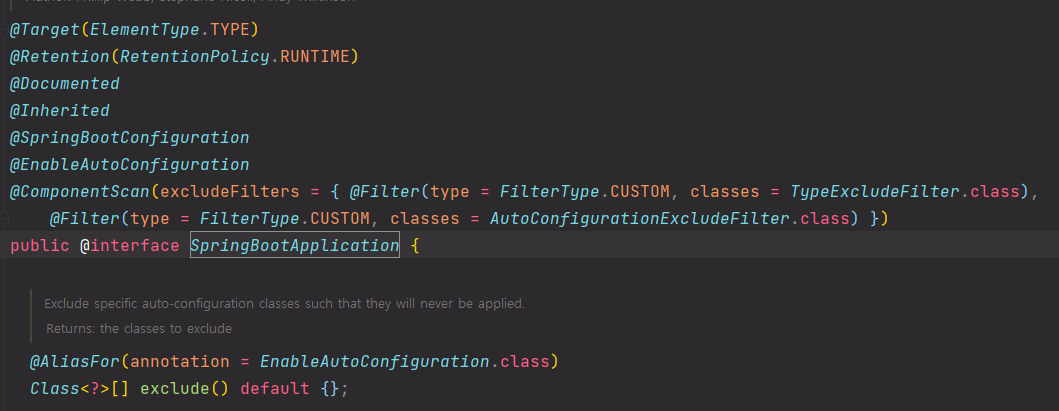
@SpringBootAplication을 Ctrl+클릭 시, 아래와 같은 구성으로 되어있다는 것을 알 수 있다.
📟 < SpringBootConfiguration >
@SpringBootConfiguration Annotation은 Spring Boot에 관련된 설정을 나타내며, 사실상 @Configuration을 확장한 것이다. 주의할 점은, 일반적으로 개발자들이 직접 사용하는 Annotation은 아니라는 것이다.
📟< ComponentScan >
@ComponentScan은 Spring에서 관리할 Bean을 찾는 역할을 한다. @Component를 상속한 다른 Annotation(@Service,@Repository,@Controller 등)을 붙인 Class를 Bean으로 등록한다.
이 Annotation은 보통 Spring Boot의 Main Class나 Setting Class에 붙여 사용한다.Spring Boot App을 생성하면 Main Class에 @SpringBootApplication Annotation이 붙는데, 이 Annoation 안에 @ComponentScan이 포함되어 있는 것이다. 그래서 따로 @ComponentScan을 사용할 필요가 없는 경우가 많다.
@Component를 포함하는 다른 Annotation들이 있으며, 이들은 개발 과정 중 특정 용도에 따라 사용된다. 몇 가지 중요한 Annotation을 간단하게 살펴보자.
Annotation
description
@Configuration
설정 파일 등록
@Repository
ORM Mapping
@Controller,@RestController
Routing 처리
@Service
Business Logic 처리
📟< EnableAutoConfiguration >
Spring Boot에서 자동 구성을 활성화하는 Annotation이다. Spring boot Server가 실행될 때 Spring Boot의 Meta file을 읽고 정의된 설정들을 자동으로 구성하는 역할을 수행한다.
예제 코드로 Bean이 어떻게 등록되는지 알아보자.
@RestController
public class TestController {
@GetMapping("/test")
public String test() {
return "Hello, world!";
}
}
@RestController Annotation은 Route 또는 Endpoint로 작동한다. 예를 들어,
@RestController Annotation이 붙은 Class 내에 정의된 test method가 /test 라는 GET 요청에 응답하도록 설정할 수 있다.
직접 살펴보면 의문이 풀릴 것이다.
하지만, 여기서 @RestController와 @Component 차이점에 대해 의문이 생길 수 있다.
이 두 Annotation은 어떻게 서로 다른 용도를 가지면서 동시에 Spring에서는 같은 방식으로 취급 될까?
@RestController Annotation을 Ctrl+클릭하면 구현하는 RestController.java file로 이동할 것이다.
코드를 보면 @Controller, @ResponseBody Annotation이 함께 있는데. 이 코드를 보면
@Controller Annotation + @ ResponseBodyt Annotation이 합쳐진 결과물이 @RestController Annotation임을 알 수 있다.
그런데 아직도 @ComPonent Annotation을 찾지 못했다.
계속해서 @Controller Annotation 구현 파일인 Controller.java File로 이동해보자.
위와 같이 @Component Annotation이 있다. 이를 통해 @Controller Annotation이 @ComponetScan을 통해 Bean으로 등록되는 이유를 알았다. 그 이유는 바로 @Controller Annotation에서 @Component Annotation을 상속하고 있기 때문이다.
앞서 소개한 @Configuration,@Repositiory,@Service Annotation 모두 @Component Annotation을 가지고 있다.
Portable Service Abstraction은 줄여서 PSA라고 부르며, '이식 가능한 서비스 추상화'라는 뜻을 가지고 있다.
이는 Spring이 제공하는 다양한 기술을 추상화하여 Dev가 쉽게 사용할 수 있는 Interface를 제공하는 것을 의미한다.
그럼 이것이 왜 필요한지, 실제로 어떻게 활용되는지 알아보자.
🔥 < PSA의 활용 예시 >
PSA는 Client의 Mapping과 Class, Method의 Mapping을 위한 Annotation을 포함한다.
그리고 Spring DataBase에 접근하기 위한 기술로는 JPA,MyBatis,JDBC 등이 있지만, 이 중 어떤 기술을 사용하더라도 일관된 방식으로 DataBase에 접근할 수 있도록 Interface를 제공한다.
또한, Web Application Server(WAS)역시 PSA의 좋은 예시라고 볼 수 있다.
PSA 덕분에 Dev는 코드 변경 없이, Tomcat,Undertow,Jetty 등 다양한 WAS에서 실행할 수 있기 때문이다.
📟 < Spring과 PSA >
Spring의 주요 개념인 IoC(Inversion of Control),DI(Dependecy Injection),AOP(Aspect-Oriented Programming),PSA(Portable Service Abstraction)은 Spring의 근간을 이루고 있다. 이러한 개념들을 활용한다면, Spring을 더욱 효과적으로 사용할 수 있게 된다.
Spring FrameWork는 IoC/DI를 통해 객체 간 의존 관계를 설정하며, AOP를 통해 핵심 관점과 부가 로직을 분리해 개발하며, PSA를 통해 추상화된 다양한 Service들을 일관된 방식으로 사용하도록 한다.
스프링에서 또 다른 중요한 개념으로는 AOP가 있다. AOP는 Aspect Oriented Programming을 줄인 표현이다.
직역하면 관점 지향 프로그래밍이다. 조금 의미를 풀어 설명하자면 프로그래밍에 대한 관심을 핵심 관점, 부가 관점으로 나누어 관심 기준으로 모듈화하는 것을 의미한다.
예를 들어 계좌 이체, 고객 관리하는 프로그램이 있을 때 각 프로그램에는 로깅 로직, 즉, 지금까지 벌어진 일을 기록하기 위한 Logic과 여러 Table을 관리하기 위한 Database Logic이 포함된다. 이때 핵심 관점은 계좌 이체,고객 관리 로직이고, 부가 관점은 로깅,데이터베이스 연결 로직이다. 실제 프로그램의 기능으로 로직을 정리하면 다음 그림과 같다.
그림 반응이 좋아서... 감사합니다..?
그림을 보면 로깅, 데이터베이스 연결은 모두 계좌 이체와 고객관리에 필요하다. 여기에 AOP 관점을 적용하면,
부가 관점에 해당하는 Logic을 modularized하여 앞에서 본 그림처럼 개발할 수 있게 해준다.
다시 말해, 부가 관점 코드를 핵심 관점 코드에서 분리할 수 있게 해준다.
그 결과 프로그래머는 핵심 관점 코드에만 집중할 수 있게 될 뿐만 아니라 프로그램의 변경과 확장에도 유연하게 대응 할 수 있어 좋다.
Spring Container는 Bean을 생성하고 관리한다. 즉, Bean이 생성~소멸까지의 Life Cycle을 이 Spring Container가 관리하는 것이다. 또한 개발자가 @Autowired 같은 Annotation을 사용해 Bean을 주입받을 수 있게 DI를 지원하기도 한다.
그럼 Bean은 무엇일까?
🤔< Bean ?>
Bean은 Spring Container가 생성하고 관리하는 객체이다.
public class A {
@Autowired
B b;
}
여기서 B가 바로 Bean이다. Spring은 Bean을 Spring Container에 등록하기 위해 XML 파일 설정, Annotation추가 등 여러 방법을 제공한다. 다시 말해 Bean을 등록하는 방법은 여러 가지 있다는 뜻.
예를 들어 MyBean이라는 Class에 @Conponent Annotation을 붙이면 MyBean Class가 Bean으로 등록된다.
이후 Spring Container에서 이 Class를 Managed 한다. 이때 Bean의 name은 Class name의 첫 글자를 소문자로 바꿔 관리한다.
지금 MyBean 같은 경우 myBean으로 된다.
@Componet //Class MyBean을 Bean으로 등록!
public class MyBean {
}
IoC는 Inversion of Control을 줄인 표현이다. 직역하자면, 제어의 역전이다.
다음을 보면 Class B object를 사용하기 위해 Class A에서 Object를 직접 생성한다.
public class A {
b = new B(); //Class A에서 new keyword로 class B의 object 생성
}
제어의 역전은 다른 객체를 직접 생성하거나 제어하는 것이 아니라, 외부에서 관리하는 객체를 가져와 사용하는 것을 말한다. 위 예제에 제어의 역전을 적용하면 다음과 같이 코드의 형태로 바뀐다. 이전과는 다르게 Class B object를 직접 생성하는 것이 아니므로, 어딘가에서 받아와 사용하고 있다고 추측해볼 수 있다. 실제로 스프링은 스프링 컨테이너가 객체를 관리,제공하는 역할을 한다.
public class A {
private B b;
}
🎶 < DI 란 ? >
앞에서 설명한 것처럼 Spring에서는 Object들을 관리하기 위해 제어의 역전을 사용한다. 그리고 제어의 역전을 구현하기 위해 사용하는 방법이 DI이다. 여기서 DI라는 개념이 등장한다. DI는 Dependency Injection을 줄인 표현이며, 직역하자면 의존성 주입이다.
DI는 어떤 클래스가 다른 클래스에 의존한다는 뜻이다. 조금 어려운 표현이겠지만 코드를 보면 매우 쉽다.
다음 코드는 IoC/DI를 기초로 하는 Spring Code이다. 여기서 사용하는 @Autowired라는 Annotation은 Spring Container에
있는 Bean을 주입하는 역할을 하는데, Bean은 Spring Container에서 Managed하는 Object이다. Bean은 바로 다음 글에 설명할 개념이므로 우선 이 정도로만 이해하도록 하자. 이전 코드에서는 개발자가 직접 B Object를 생성했지만,다음 코드는 어딘가에서 B b;라고 선언했을 뿐 직접 객체를 생성하지는 않고 있다. 다시 말해 Object를 주입받고 있다.
public class A {
// A에서 B를 주입받음
@Autowired
B b;
}
위와 같이 코드를 작성해도 프로그램은 잘 동작한다. 그 이유는 Spring Container라는 곳에서 Object를 주입했기 때문이다.
쉽게 말해 Spring Container가 B Object를 만들어 Class A에게 준 것이다.
그림처럼 기존의 Java Code는 Class A에서 B Object를 쓰고 싶은 경우 직접 생성했지만, Spring의 경우 Class A에서 B Object를 쓰고 싶은 경우 Object를 직접 생성하는 것이 아니라 Spring Container에서 Object를 주입받아 사용한다.
이 IoC/DI 개념은 Spring의 핵심 개념이라고 할 수 있을 만큼 중요하기에 반드시 이해해야 한다.
DataBase는 현대 Business의 핵심 요소 중 하나이다. 기업은 수십, 수백, 심지어는 수억 개의 Recode를 관리해야 할 수도 있다. 이런 Data를 효과적으로 관리하려면 구조화된 방식이 필요하고, 그래서 RDBMS를 사용하고 있다.
RDBMS에서 가장 기본 개념 중 하나가 바로 "Join"이다.
📟 < Join! >
Join은 여러 Data Table을 관련성이 있는 Column을 기준으로 연결하는 방법이다. 이를 통해 단일 쿼리로 여러 Table의 Data를 수집할 수 있게 된다. 대표적으로 INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN 등이 있다.
이제 INNER JOIN부터 해서, FULL JOIN까지 자세히 알아보자.
🔥 < Inner Join >
Inner Join : "두 개 이상"의 Table에서 공통으로 존재하는 Recode만을 반환한다.
Inner Join은 Join 방식 중 가장 엄격한 일치 조건을 필요로 한다. 즉, Join 하는 Table 간에 일치 값이 없다면 결과는 아무것도 표시되지 않는다.
🌈 < Inner Join 장점 >
정확성 : Table 간에 완벽 일치하는 Recode를 반환하기에, 정확성을 보장한다.
효율성 : 불필요한 Recode를 제거함으로써 Database 효율성을 높인다.
간결성 : Inner Join을 통해 여러 Table 관련 정보를 한 줄의 Query로 가져온다.
< 예제 SQL >
'Employees' 'Departments' Table이 있다.
< Employees Table>
EmployeeID
EmployeeName
DepartmentID
1
김남준
100
2
윤태영
200
3
김태형
300
4
김지민
400
< Departments Table >
DepartmentID
DepartmentName
100
HR
200
Sales
300
IT
500
Marketing
다음 SQL Query는 Inner Join을 사용하여 'Employees' Table과 Departments Table을 Join 하고, 각 직원의 이름과 해당 직원이 속한 부서의 이름을 반환한다.
SELECT Employees.EmployeeName, Departments.DepartmentName
FROM Employees
INNER JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
이 쿼리의 결과 Table은 다음과 같다.
EmployeeName
DepartmentName
김남준
HR
윤태영
Sales
김태형
IT
여기에서 "김지민"은 결과에 제외되어있다. 이유는 그의 DepartmentID인 400은 Departments Table에 존재하지 않기 때문이다. 이처럼 INNER JOIN은 양쪽 테이블에서 일치하는 레코드만 반환한다.
다른 예제를 또 보자면, 이번에는 Employees Table에서 DepartmnetID가 200 이상인 직원과 그들의 부서를 찾는 쿼리다.
SELECT Employees.EmployeeName,Departments.DepartmentName
FROM Employees
INNER JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID
WHERE Employees.DepartmentID >= 200;
Left Join은 SQL의 주요 명령어 중 하나로, Left Table의 모든 Recode와 Right Table에서 일치된 Recode를 반환해준다.Right Table에서 일치하는 Recode가 없으면 null값.
🐱👤 < Left Join 장점 >
완정성 : Left Table의 모든 Data를 보존하면서 동시에 Right Table의 일치 데이터를 가져올 수 있다. 이는 데이터 완전성을 보장한다.유연성 : 일치하는 Data가 없더라도 Left Table의 Data를 모두 표시한다. 이로 인해 데이터 분석 시 유연성을 제공한다.
< 예제 SQL >
(앞서 언급한 Employees Table과 Departments Table을 다시 사용한다)
아래의 SQL Query는 Left Join을 사용하여서 Employees Table과 Departments Table을 Join 해서 각 직원의 이름과 해당 직원이 속한 부서의 이름을 반환한다.
SELECT Employees.EmployeeName, Departments.DepartmentName
FROM Employees
LEFT JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
이 Query의 결과는 다음과 같다.
EmployeeName
DepartmentName
김남준
HR
윤태영
Sales
김태형
IT
김지민
NULL
여기서 김지민의 부서 이름이 NULL로 표시된다. 왜냐하면 김지민의 DepartmentID인 400이 Departments Table에 존재하지 않기 때문이다.
다른 예제를 보자. 이번에는 Employees Table에서 DepartmentID가 200 이상인 직원과 그들의 부서를 찾는 Query다.
SELECT Employees.EmployeeName, Departments.DepartmentName
FROM Employees
LEFT JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID
WHERE Employees.DepartmentID >= 200;
이 Query의 결과는 다음과 같다.
EmployeeName
DepartmentName
윤태영
Sales
김태형
IT
김지민
NULL
이와 같이, Left Join은 Left Table의 모든 Recode를 보존하면서도 Right Table의 일치하는 Recode를 가져오므로
데이터의 완정성을 유지하면서 동시에 필요한 정보를 추출할 수 있다.
🔥< Right Join>
Right Join은 SQL의 주요 명령어 중 하나로, Right Table의 모든 Recode와 Left Table에서 일치된 Recode를 반환한다.
Left Table에 일치 Recode가 없으면 Null값.
🐱🏍 < Right Join 장점 >
Right Table 중심 : Right Table의 모든 Data를 보존과 동시에 Left Table Data를 가져온다.
이는 Right Table에 중점을 두면서 Data를 조사하려는 경우 유용하다.
유연성 : 일치하는 Data가 없더라도 Right Table의 Data를 모두 표시한다. 이로 인해 데이터 분석 시 유연하다.
< 예제 SQL >
( Employees와 Departments Table을 다시 사용한다 )
아래의 SQL Query는 Right Join을 사용하여서 Employees Table과 Departments Table을 Join 하여서, 각 직원 이름과 해당 직원이 속한 부서의 이름을 반환한다.
SELECT Employees.EmployeeName, Departments.DepartmentName
FROM Employees
RIGHT JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
이 Query의 결과는 아래와 같다.
EmployeeName
DepartmentName
김남준
HR
윤태영
Sales
김태형
IT
NULL
Marketing
여기서 Marketing 부서는 직원이 없기 때문에 EmployeeName은 NULL 표시된다.
이번에는 Departments Table에서 DepartmentID가 200 이상인 부서와 그 부서에 속한 직원들을 찾는 Query다.
SELECT Employees.EmployeeName, Departments.DepartmentName
FROM Employees
RIGHT JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID
WHERE Departments.DepartmentID >= 200;
이 Query 결과 Table은 아래와 같다.
EmployeeName
DepartmentName
윤태영
Sales
김태형
IT
NULL
Marketing
이처럼, Right Join은 Right Table의 모든 Recode를 보존함과 동시에 Left Table의 일치 Recode를 가져오므로, 완정성 유지와 필요 정보를 추출할 수 있다.
Enterprise Application은 대규모의 복잡한 데이터를 관리하는 Application을 말한다.
소프트웨어 분야가 발전하며 Enterprise App은 점점 복잡해졌다. 예를 들어 은행 시스템을 생각해보면 몇 백만, 몇천만 사용자가 잔고 조회,입금,출금 요청을 한다. 이렇듯 Enterprise App은 많은 사용자의 요청을 동시 처리 해야 하므로 서버 성능,안정성,보안이 매우 중요하다고 볼 수 있다.
그런데 이런 것들을 신경쓰면서 사이트 기능, 즉, Business Logic까지 개발하기는 매우어렵다.
누군가 Enterprise App을 위한 개발 환경을 제공해서 기능 개발에만 집중할 수 있다면 얼마나 좋을까?
이런 상황에서 Spring Framework가 등장 했다. Spring framework는 앞서 언급한 서버 성능,안정성,보안을 매우 높은 수준으로 제공하는 도구였다. 덕분에 개발자들은 기능 개발에만 집중할 수 있게 되었다.
📟< 스프링을 더 쉽게 만들어주는 스프링 부트 >
스프링은 장점이 많은 개발 도구이지만 설정이 매우 복잡하다는 단점이 있었다. 그래서 스프링을 개발팀에서도 이런 단점을 인식하고 단점으로 보완하고자 스프링 부트를 출시했다. 스프링 부트는 스프링 프레임워크를 더 쉽고 빠르게 이용할 수 있도록 만들어주는 도구이다. 빠르게 스프링 프로젝트를 설정할 수 있고 의존성 세트라고 불리는 스타터를 사용해 간편하게 의존성을 사용하거나 관리할 수 있다. 스프링 부트는 개발자가 조금 더 Business Logic 개발에만 집중할 수 있도록 만들어주는 도구인 것이다. 스프링과 비교했을 때 Springboot의 주요 특징은 다음과 같이 정리할 수 있다.
①.Tomcat,Jetty,Undertow 같은 웹 애플리케이션 서버 (Web application server, WAS)가 내장되어 있어 따로 설치하지 않아도 독립적으로 실행할 수 있다. ②.Bulid 구성을 단순화 하는 Spring boot Starter를 제공한다. ③.XML 설정을 하지 않고 Java code로 모두 작성할 수 있다. ④.JAR를 이용해서 Java Option만으로도 배포가 가능하다. ⑤.App의 Monitoring 및 Manage tool인 Spring Actuator를 제공한다.
🎯참고로 Spring boot와 Spring은 서로 다른 도구가 아니라 Spring boot는 Spring에 속한 도구이다. 단, Spring과 Spring boot는 개발할 때의 몇 가지 차이점이 있다. 그 차이점에 대해서 알아보자.
🌳<Spring과 Spring boot의 차이점 >
< 구성의 차이 >
Spring은 App 개발에 필요한 환경을 수동으로 구성하고 정의해야 한다. 하지만 Spring boot는 Spring core와 Spring MVC의 모든 기능을 자동으로 로드하므로 수동으로 개발 환경을 구성할 필요가 없다.
< 내장 WAS 유무 >
Spring App은 일반적으로 Tomcat과 같은 WAS에서 배포된다. WAS란 간단히 Web App을 실행하기 위한 장치를 말한다.
하지만 Spring boot는 자체적으로 WAS를 가지고 있다. 그래서 jar file만 만들면 별도의 WAS setting을 하지 않아도 App을 실행할 수 있다. 참고로 Spring boot의 내장 WAS에는 Tomcat,Jetty,Undertow가 있어 상황에 필요한 WAS를 선택할 수도 있다. 그 외의 차이점 아래의 표와 같다.