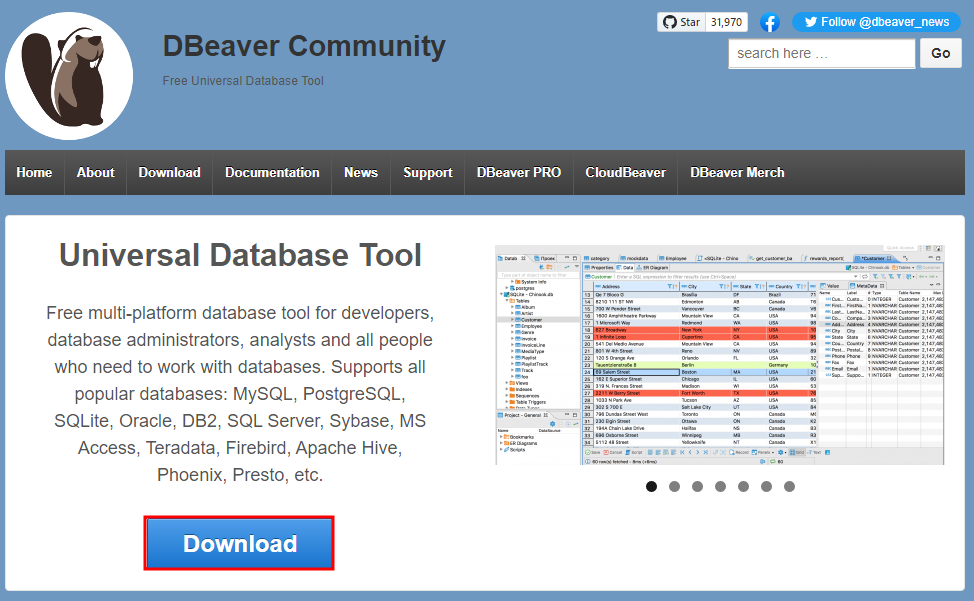
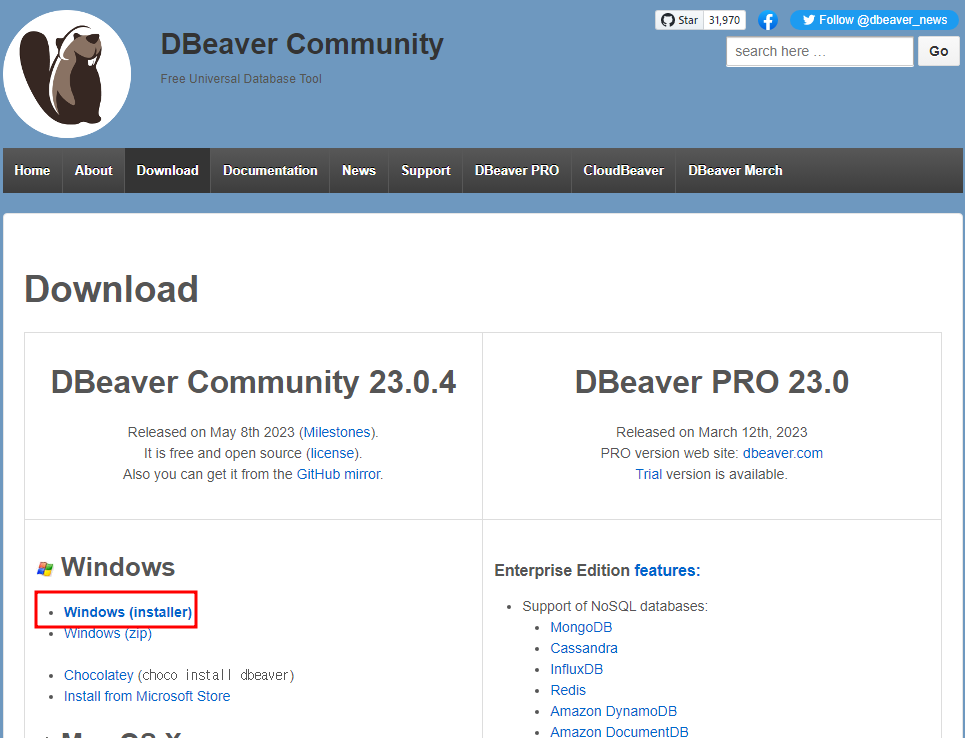
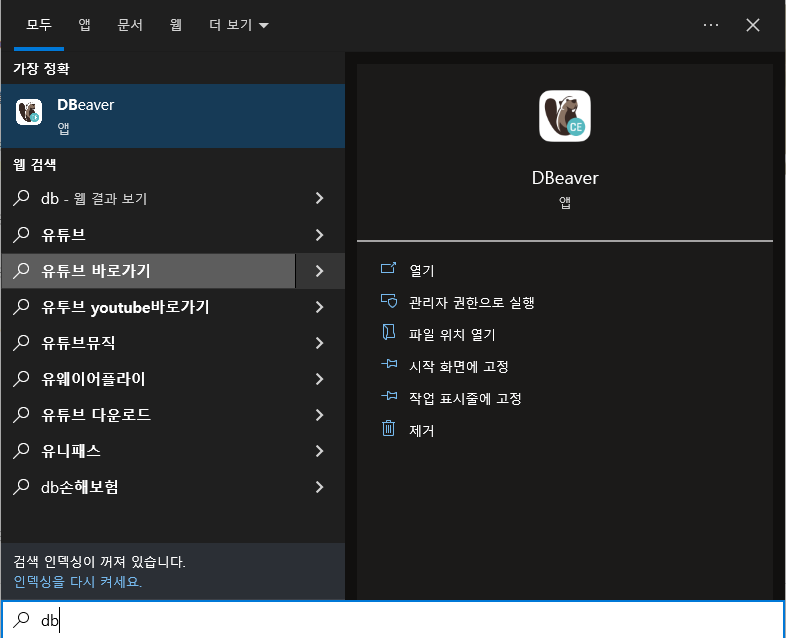
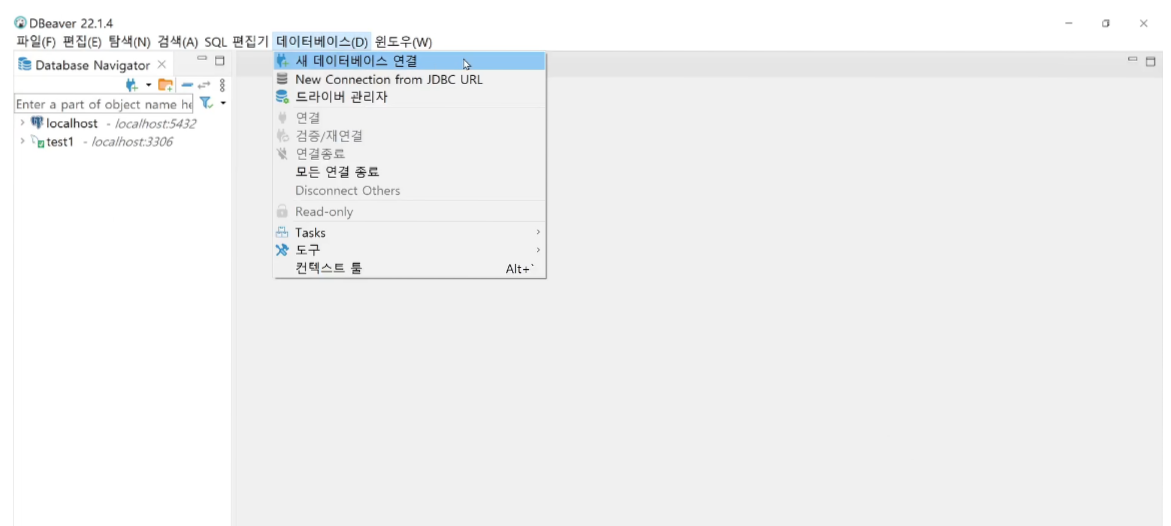
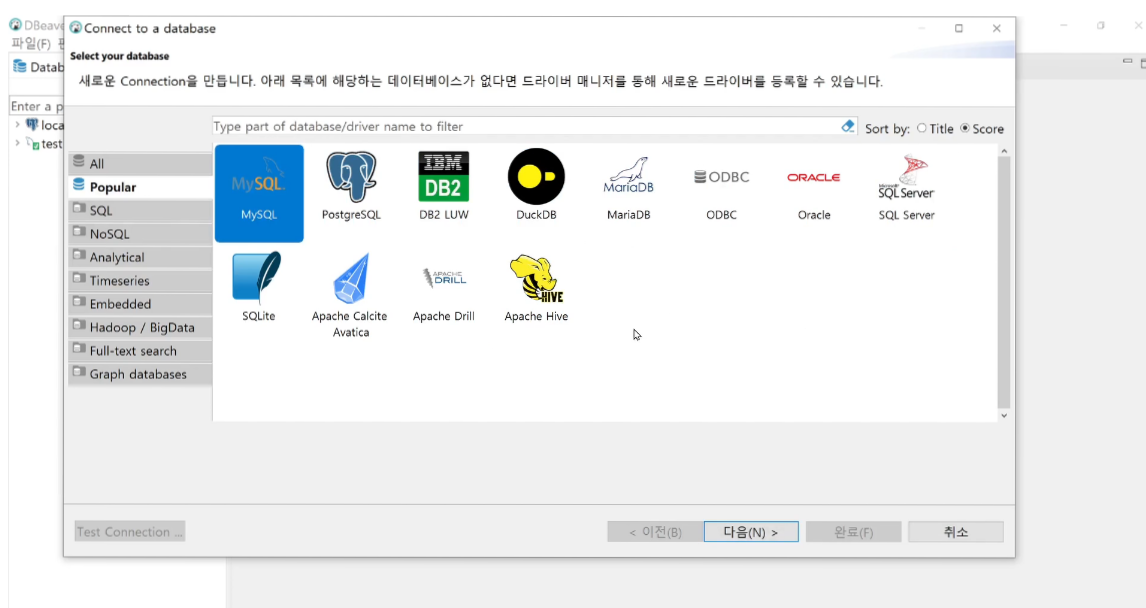
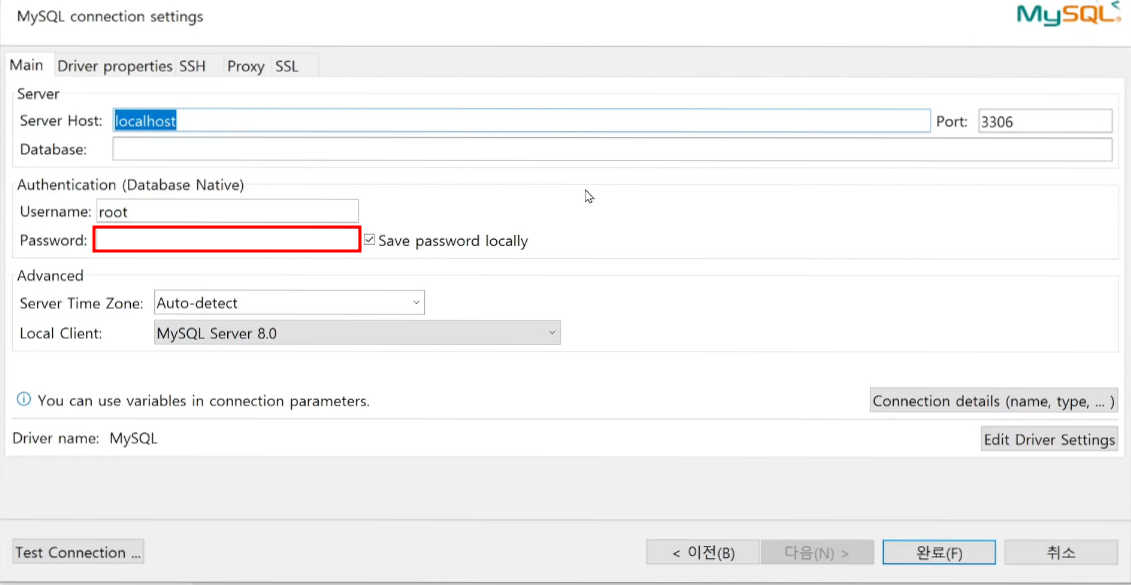
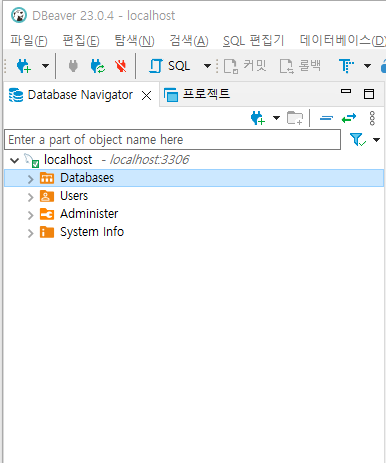
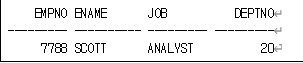
인지 심리학에서 개발된 이론 중 하나. 이 이론은 인간이 자연환경에서 쉽게 주의를 회복할 수 있다는 것을 제안하고 있다.
ART는 자극에 따른 주의력의 회복력을 설명하기 위해 개발되었다.
일상적으로 우리는 매 순간 다양한 정보들로부터 주의력을 요구받고 있다.
그리고 이러한 정보들은 우리의 주의력을 소모시킨다. 이때 우리는 자연환경에서 적극적으로 주의력을 회복할 수 있다는 것이 ART의 핵심 개념이다.
ART는 자연환경에서 주의력 회복이 쉬운 이유를 설명하기 위해 "인지 피로"와 "자연 요소"라는 개념을 도입한다.
인지 피로란, 지속적인 정보처리와 주의력의 소모로 인해 인간이 느끼는 피로감을 의미한다. 반면 자연 요소는, 자연환경에서 경험할 수 있는 자극들 중에서 인간의 주의를 자연스럽게 끌어당기고 회복시킬 수 있는 것들을 의미한다.
따라서 ART는 인간의 주의력이 회복되어야 할 때, 자연환경에서의 휴식과 레저활동 등이 유용하다는 것을 제안하고 있다.
이를 통해 인간의 인지 피로를 최소화하고 주의력을 회복할 수 있는 환경을 제공하는 것이 중요하다는 것을 강조한다.

< 관련 논문 >
The Differential Impact of Mystery in Nature on Attention: An Oculometric Study
The Differential Impact of Mystery in Nature on Attention: An Oculometric Study
'일반지식,상식,논문' 카테고리의 다른 글
| ㅎㅏㄴㄱㅡㄹㅇㅣ ㅇㅣㅅㅏㅇㅎㅏㄱㅔ (한글 키보드 오류 해결 방법) (0) | 2023.05.14 |
|---|---|
| 대한민국 3.1절의 의미 (0) | 2023.04.21 |
| 북극 북극항로/우주방사선 논문 (0) | 2023.04.21 |
| 일 잘하고 성공하는 심리학 (0) | 2023.04.21 |
| 50분 수업, 10분 휴식을 갖는 이유 (0) | 2023.04.21 |