아래와 같이 코드를 만들고, Solution Bulid를 하면, 빌드가 성공 되는 걸 볼 수 있다.
이제 잘 생성이 되었는지, 확인을 해보아야 한다. 솔루션 탐색기(단축기 Ctrl+;)을 열어, 아래와 같이
파일 탐색기에서 폴더 열기를 클릭 한다. 그럼 파일 탐색기가 자동으로 해당 파일이 존재하는 디렉토리까지 열어준다.
이후 아래와 같은 폴더가 열리는데, bin->Debug->net7.0으로 이동 시, 빌드한 Hello가 생성되어있다.
실행하기 위해선 Window키(컨트롤 키 옆)+ R키를 누르면 실행 창이 뜨는데, cmd를 누르고 엔터를 한다. 그다음 cmd 창에 cd를 입력 해주고, 이전에 Hello 경로를 복사 후에 붙여넣기를 하고, 엔터를 누르면 2번째 사진의 맨 아래와 같이 뜬다.
이후 dir로 통해, 디렉터리를 확인할 수 있고,list up할 수 있다. Hello.exe로 VS에서 인자의 개수가 0이면, 해당 메세지를 출력하도록 구현 한 것이 출력 된다.
아래와 같이 Hello.exe 뒤에 인자를 넣으면 다르게 출력 된다.
< 소스 분석 >
< using System; >
using : C# 키워드 중 하나. 어느 코드 요소에 'using'이라고 이름을 붙이면 컴파일러는 C#의 키워드가 사용됐음을 알아보고 실행 파일 대신 에러메세지를 내뱉을 것이다. 아무튼 using이라는 뜻을 뭔가를 사용하는 것 같은데, 그 뒤에 따라오는 System을 사용하겠다. 라는 것이다.
System : 이것은 C# 코드에 기본적으로 필요한 클래스를 담고 있는 네임스페이스이다. 따라서 using System은 System 네임스페이스 안에 있는 클래스를 사용하겠다고 컴파일러에게 알리는 역할을 한다. 만약 이 문장을 생략했더라면, 13행의
Console.WriteLine ...; 코드는 System.Console.WriteLine.;..;으로 글자 수가 늘어났을 것이다. 앞에서 System 네임스페이스를 사용하겠다고 선언한 덕에 코드의 양을 줄일 수 있게 되었다.
< using static System.Console; >
using static System.Console은 Console.WriteLine...을 WriteLine으로 줄여주는 것이다. 위의 코드에서 17행에 있는 WriteLine...;이 바로 이 문장의 덕을 본 사례이다. (13행도 줄일 수 있다.)
using static은 어떤 데이터 형식(예: 클래스)의 정적 멤버를 데이터 형식의 이름을 명시하지 않고 참조하겠다고 선언하는 기능을 한다.
< namespace Hello { } >
네임스페이스는 성격이나 하는 일이 비슷한 클래스,구조체,인터페이스,대리자,열거 형식 등을 하나의 이름 아래 묶는 일을 한다. 예를 들어 System.IO 네임스페이스에는 파일 입출력을 다루는 각종 클래스, 구조체,대리자 형식 등이 있고, System.Printing 네임스페이스에는 출력에 관련한 일을 하는 클래스 등이 소속되어 있다. .NET 클래스 라이브러리에 1만 개가 훨씬 넘는 클래스가 있어도 프로그래머가 전혀 혼돈을 느끼지 않고 이 클래스를 사용할 수 있는 비결은 바로 이렇게 각 용도별/분야별로 정리되어 있는 네임스페이스에 있다.
이 광경은 1946년 최초의 컴퓨터 에니악(ENIAC)을 운용하던 모습이다. 한쪽 벽면을 가득 메운 상자들은 에니악이고, 전기 배선은 에니악이 계산할 때 사용하는 회로로 현대 컴퓨터로 치자면 '프로그램(Program)이었다. '프로그래밍(Progoramming)'이 프로그램을 제작하는 일을 뜻하므로 그 당시 연구원이 하던 에니악의 전기 배선 작업은 일종의 프로그래밍이었다고 할 수 있다.
에니악은 당시에는 뛰어난 계산 능력을 갖고 있었지만, 기계가 갖고 있던 문제 또한 컸다.
뜨거운 진공관을 식히기 위해 거의 매일 반나절은 운영을 멈춰야 했으며, 프로그램을 변경하려면 6,000개나 되는 배선
교체해야 했다.
하지만 이런 고민들은 1951년, 존 폰 노이만(John von Neumann)의 혁신적인 설계 아이디어를 통해 해결되었다. 그의 개선안이 적용된 Eniac의 후속 모델인 EDVAC은 중앙처리장치,기억 장치,프로그램,데이터로 이루어진 구조로 재탄생하며 모든 현대 컴퓨터의 조상이 되었다.
< 프로그래밍 언어의 출현 >
그럼에도 불구하고, 1950년대까지는 컴퓨터 발전은 하드웨어 위주로 이루어지고,프로그래밍은 비트(Bit)를 조합하는 기계어 수준에 머물렀다. 이 상황에서 언어의 진전은 비트를 기록하는 방식에서 카드에 구멍을 뚫어 비트를 기록하는 방식으로 바뀌었다. 이것을 사람의 언어로 비유하면, '앞으로 가라'는 짧고 간결한 표현 대신, 매우 세세하게 동작을 설명하는 것과 같다.
"허리를 바로 세우고 왼팔을 앞으로 내저으며 오른팔을 뒤로 내저어라. 동시에 몸의 중심을 앞으로 옮기며 왼발을 받침으로 삼고 오른발을 앞으로 내밀어라. 그리고 별도의 지시가 있기 전까지 이 행동을 계속하라."
사람이면 이해하고 수행하는데 문제가 없겠지만, 컴퓨터는 명확한 지시 없이는 아무것도 할 수 없다. 이 문제를 해결하기 위해 등장한 것이 어셈블리어였다.
< 어셈블리어? >
어셈블리어는 복잡한 기계어 명령을 사람이 이해할 수 있는 기호나 단어로 대체했다. 기계어 명령어 '01001100 00001000 100000001100100000'를 어셈블리어에서는 'MOV'로 표현할 수 있다. 이렇게 변환된 명령어는 훨씬 간결하고 이해하기 쉽다.
그러나 컴퓨터는 'MOV'를 이해할 수 없다. 컴퓨터는 오직 0과 1만 이해할 수 있기 때문에, 어셈블리어로 작성된 코드는 컴파일 과정을 거쳐 기계어로 변환되어야 한다. 이 과정에서는 컴파일러라는 소프트웨어가 사용되는데, 이 컴파일러는 소스 코드를 기계어로 변역해서 실행 파일을 만들어내는 역할을 한다.
< 컴파일러 vs 인터프리터 >
컴파일러는 소스 코드를 기계어로 변환하여 실행 파일을 생성하는 반면, 인터프리터는 소스 코드를 실시간으로 해석하여 실행한다. 그래서 컴파일러는 소스 코드를 실행파일로 변환하는 과정이 필요하지만, 인터프리터는 이 과정 없이 바로 코드를 실행할 수 있다.
이러한 차이 때문에, 컴파일러 방식에서는 오류 수정이 상대적으로 번거롭지만, 인터프리터 방식에는 바로 실행 가능하므로 개발 속도가 빠르다. 이런 특징 때문에 최근에는 PHP,Python,Ruby등 인터프리터 방식의 언어가 많이 사용되고 있다.
< 포트란의 탄생 >
1948년, 컴퓨터는 기술적으로 그 발명에 비견할 만한 도약을 하게 된다. 트랜지스터가 등장하며 진공관의 종말을 고했고 곧이어 수천, 수만 개의 트랜지스터를 하나의 칩에 집적한 마이크로 칩이 발명되면서 컴퓨터는 급속도로 발전해 나갔다.
성능은 빠른 속도로 향상됐으며 가격은 빠른 속도로 하락했다. 컴퓨터의 보급 속도가 빨라진 것은 말할 것도 없다.
컴퓨터 시장이 확대되면서 많은 돈이 컴퓨터 산업계에 유입됐고, 이 돈은 다시 더 향상된 컴퓨터를 개발하기 위한 연구에 투입됐다.
컴퓨터가 널리 보급되면서 사람들은 더 많은 업무를 컴퓨터로 해결하고 싶어졌다.
그런데 문제가 생겼다. 사람들에게 필요한 프로그램은 빠르게 늘어가는데, 아무리 똑똑한 프로그래머라 해도 기호와 다름없는 어셈블리어로는 그 프로그램들은 빠르게 만들 수 없었던 것이다.
프로그래밍 언어가 이렇게 어렵게 생겼으니, 프로그래밍 전문 과학자나 아주 똑똑한 사람들의 전유물인 것은 당연한 일이었다. 하지만 John Backus가 이 상황을 상당 부분 바꿔놓았다. 그는 IBM에 입사하자마자 당시 한창 개발 진행 중이던 일종의 어셈블리어 번역기인 스피드 코딩 프로젝트에 참여했다. 그리고 1957년, 스피드 코딩 프로젝트 경험을 기반으로 사람의 언어에 가까운 최초의 프로그래밍 언어, 포트란(Fortran)과 컴파일러를 개발했다. 포트란은 연구소와 과학 기술자를 중심으로 엄청난 인기를 얻어나갔다. 그 인기 요인은 무엇이었을까?
[5+1 식을 계산하는 포트란 코드 예제]
a = 5 + 1
앞의 어셈블리 코드와 비교하면, 더 단순해질 수 없을 정도로 단순해졌다. 기계어와는 비교 할 수 없을 정도로 훌륭하다.
프로그래밍 코드답게 생긴 것은 앞에서 선보인 어셈블리어쪽이지만, 이해하기에는 포트란 쪽이 훨씬 낫다.
포트란은 수학 시간에 배운 덧셈과 등가 기호만으로도 덧셈 연산이 가능하다. 이러한 포트란의 성공은 다른 컴퓨터 과학자들을 자극했고, 이후 이들에 의해 1천여 가지가 넘는 프로그래밍 언어들이 탄생하고 또 사라져 갔다.
< 매우 쉽게 프로그래밍할 수 있게 한 베이직 >
1964년, 베이직(BASIC, Beginner's All - Purpose Symbolic Instruction code)언어가 미국 다트머스 대학의 존 케머니와 토마스 커츠 교수에 의해 탄생했다. 이들은 컴퓨터 프로그래밍이 더 이상 과학자나 엔지니어의 전유물로 남지 않기를 바랬다. 그래서 누구라도 배워 사용할 수 있는 언어를 고안했는데, 이것이 바로 베이직이다. 베이직 언어는 너무 사용하기 쉬웠기에 수많은 컴퓨터광을 프로그래밍의 세계로 끌여들였다.
레이크사이드 스쿨에 다니던 초등학생 빌 게이츠와 폴 앨런도 프로그래밍에 이끌린 컴퓨터광 중 한명이었다. 당시 컴퓨터는 엄청나게 비싼 기계였지만 레이드사이드 스쿨은 재정적으로 풍부한 사립학교 였고, 어머니회의 후원으로 컴퓨터와 터미널을 보유할 수 있었다. 빌 게이츠와 그의 친구들은 하루 종일 베이직 프로그래밍에 빠져들었다. 빌 게이츠는 학교를 졸업하고 하버드에 진학 했지만, 얼마 가지 않아 학업을 중단하고 폴 앨런과 함께 1975년 마이크로소프트를 창업했다. 그렇게 탄생한 마이크로소프트의 첫 번째 제품이 바로 베이직 인터프리터(BASIC Interpreter)이다.
마이크로소프트의 베이직은 IBM이 개발한 PC에 이식됐고, 많은 프로그래머의 손에 의해 PC에서 사용되는 수많은 응용 프로그래밍을 탄생 시켰다. 또한 1990년대 들어 마이크로소프트가 윈도우를 출시 했을때 비주얼 베이직(Visual Basic)으로 새롭게 거듭나면서 윈도우 응용 프로그램을 보급하는 일등 공신이 됐으며, ASP(Active Server Pages)라는 웹 응용 프로그래밍 언어로 사용되면서 인터넷 시대의 발전을 촉진한 스타로 자림매김했다. 현재 마이크로소프트 베이직 언어의 최신 버전은 비주얼 베이직 2019이며, 탄생한 지 50여 년이 지났음에도 여전히 많은 프로그래머에게 사랑받고 있다. 하지만 아쉽게도 2020년 3월에 마이크로소프트는 비주얼 베이직의 언어적 진화는 지원하지 않을 것이라고 공식 발표했다.
< 유닉스의, 유닉스에 의한, 유닉스를 위한 C >
1964년, MIT 공대와 AT&T 벨 연구소, 그리고 GE는 멀틱스(Multics)라는 운영체제 개발을 시작했다. 멀틱스는 GE의 메인 프레임 컴퓨터를 위한 운영체제로서 획기적인 성능과 기능을 목표로 했다.
우수한 연구진과 막대한 비용을 투입했음에도, 멀틱스는 결국 실패하고 말았다. 비록 프로젝트는 실패했지만, 이 프로젝트에 참여했던 벨 연구소의 데니스 리치와 켄 톰슨은 운영체제 개발이라는 소중한 경험을 안고 회사로 돌아왔다.
벨 연구소로 돌아온 켄 톰슨은 어느 날 연구소의 한쪽 구석에서 놀고 있는 미니 컴퓨터 PDP-7을 발견했다. 어마어마했던 멀틱스 프로젝트에 질린 켄 톰슨은 PDP-7을 가지고 작지만 쓸모 있는 프로그램을 만들어 보고 싶어 어셈블리어로 < 우주 여행 > 이라는 게임을 작성했다. PDP-7에서 프로그램을 하나 완성하자 켄 톰슨은 다시 한번 운영체제 개발에 도전해보고자 데니스 리치와 함께 유닉스를 만들기로 한다.; 그렇게 PDP-7에서 유닉스의 첫 버전이 만들어졌다.
이후 리치와 톰슨은 PDP-11 버전을 만들면서 새로운 언어도 만들기로 결심했다. 어셈블리어는 코드 생산성이 너무 낮았고, 당시 사용하던 B 언어(켄 톰슨의 개발)는 PDP-11의 새로운 기능을 활용하는 데 역 부족이었기 때문이다. 그래서 데니스 리치는 B 언어의 특징을 물려받은 새로운 프로그래밍 언어를 개발했고, B언어를 계승한다 하여 'C 언어'라 이름 붙였다.
C언어를 개발한 뒤 리치와 톰슨은 유닉스를 통째로 C 언어로 재작성 했다. CPU마다 명령어가 달라지는 어셈블리어로는 다양한 컴퓨터에 유닉스와 응용 프로그램들을 이식하는 것이 매우 어려웠기 때문이다. AT&T 벨 연구소는 소스 코드를 비롯한 유닉스의 모든 것을 공개하며 미국 내 대학과 기업에 공급했다. 유닉스는 미니 컴퓨터에 쓸 만한 운영체제를 찾던 사람들에게 큰 환영을 받았으며, C 언어로 만들어졌기 때문에 다른 컴퓨터로의 이식이 용이했다. 각 대학과 기업은 소유하고 있던 미니 컴퓨터에 유닉스를 이식하여 사용했으며, 이 과정에서 .C언어도 자연스럽게 함께 보급됐다. 그리고 유닉스가 주류 운영체제로 자리잡으면서 C 언어도 '유닉스의 언어'에서 '프로그래머의 언어'로 자리잡게 됐다.
< C+1 == C++ >
C++('씨 플러스 플러스'라고 읽는다.)는 AT&T 벨 연구소(C와 출신이 같다.)의 바야네 스트롭스트룹(Bjarne Stroustrup) 교수가 객체지향 프로그래밍(Object Oriented Programming)이 가능하도록 C를 개선 시킨 프로그래밍 언어 이다.
'C++'에서 ++는 자기 자신을 1만큼 증가시킨다는 뜻으로, C언어 에서 사용되는 연산자이다. 즉, C++는 C를 향상시킨 프로그래밍 언어라는 의미를 가지고 있다.
C언어는 B언어의 다음 알파벳을 사용했는데, C++.는 왜 D가 아니고 C++일까? 그것은 C++언어가 C 언어를 거의 계승하고 필요한 만큼만 향상시켰기 때문이다. 1979년에 만들어진 C++는 기존 C언어 코드를 대부분 그대로 사용할 수 있으며, 객체 지향 프로그래밍을 지원해 프로그래머가 거대하고 복잡한 소프트웨어를 이전보다 쉽게 만들 수 있도록 했다. 이러한 매력 때문에 C++는 많은 프로그래머,마이크로소프트 오피스를 비롯한 많은 상용 소프트웨어가 바로 이 언어로 작성 됐다.
< 더 나은 세상을 위한 C# >
++ 밑에 ++를 더 붙이면 #이 된다. C#이라는 이름은 C++를 계승한다는 의미로 붙여진 것이다.
하지만 C#과 C나 C++와는 여러 면에서 차이가 있다. 우선 C와 C++가 AT&T 벨 연구소에서 탄생한 반면, C#은 마이크로소프트의 앤더스 헤일스버그가 만들었다. C 언어로 작성된 소스 코드는 C++ 컴파일러가 컴파일할 수 있지만, C나 C++로 작성된 소스 코드는 C#에서 컴파일되지 않는다., 이름은 비슷하지만 실제로는 완전히 다른 언어라는 것이다.
1990년대 말, 마이크로소프트는 .NET('닷넷'이라고 읽는다.')비전을 발표했다. 이 비전을 요약하자면 앞으로의 인터넷 서비스는 모든 종류의 기기에서 사용할 수 있어야 하며, 마이크로소프트의 .NET은 이를 위한 플랫폼이라는 것이었다. 하지만 마이크로소프트가 .NET을 위해 준비한 것 중 대부분은 사람들의 별다른 관심을 끌지 못했다. 엄청난 투자를 생각하면 사업적인 면에서는 실패했다고 평해도 틀린 말은 아닐것이다.
하지만 .NET은 프로그래머들에게 소중한 선물을 안겨줬는데. 바로 .NET 클래스 라이브러리와 C#프로그래밍 언어이다. .NET 클래스 라이브러리는 콘솔, 데스크톱, 웹, 모바일 등에서 동작하는 애플리케이션을 손쉽게 개발할 수 있는 API를 제공한다. C# 프로그래밍 언어는 .NET에 최적화된 언어로서 프로그머의 생산성을 보다 높은 수준으로 끌어올렸다.
(Dev 지식으로서의 자료구조 및 알고리즘 개념 설명. 글 아래의 개념을 이해하고, 자료구조,알고리즘 카테고리에 관련한 글을 같이 읽으면 좋다.)
자료구조란 데이터에 편리하게 접근하고, 변경하기 위해서 데이터를 저장하거나 조작하는 방법을 말한다.
만약에 사과를 담는 용기가 필요하다고 생각해보자. 사과를 멀리 가지고 가려는 목적이라면 바퀴가 달려있는 수레 같은게 필요할 수 있다. 자주자주 꺼내 먹기 위한 용기가 필요하다면 손을넣어 꺼낼수있는 백이나 바구니 같은 형태가 적합하다고 할수있겠다.어떤 자료구조를 선택하느냐에 따라 퍼포먼스가 달라진다.
알고리즘이란 어떠한 문제를 해결하기 위한 일련의 절차나 방법을 공식화한 형태로 표현한 것을 의미한다.
알고리즘은 9세기 페르시아의 수학자인 무함마드 알콰리즈미의 이름을 라틴어화한 알고리스무스(Algorismus)에서 유래한 표현이다. 유한성을 가지며, 언젠가는 끝나야 하는 속성을 가지고 있다. 문제 해결을 위해 여러 개의 후보 알고리즘 중, 정확성과 효율성 등을 평가한 후에 최적의 알고리즘을 선택한다. 알고리즘은 연산, 데이터 진행 또는 자동화된 추론을 수행한다.
자료구조와 알고리즘의 관계
자료구조는 '데이터의 표현과 저장방법'을 의미한다고 하였다. 그렇다면 알고리즘은 무슨 의미일까? 사람들은 알고리즘을 공부하려면 자료구조를 공부해야한다고 한다. 알고리즘은 그러한 데이터를 대상으로 '문제의 해결 방법'을 의미한다.
예를들어 배열에 값을 저장하는 것은 자료구조적이지만, 그 배열을 통해서 총합을 구하는 코드는 알고리즘적인 코드라고 할 수 있다.
< 자료구조와 알고리즘이 필요한 이유 >
1. 메모리를 절약하기 위해
가장 기본적인 이유이며 불필요하고 추가적인 정보 없이 목적에 부합하는 정보만을 저장하면 되기 때문에 저장 공간을 효율적으로 사용할 수 있다.
2. 프로그램 실행 시간을 단축하기 위해
효율적은 구조를 구현함으로 불필요한 계산을 줄이고 프로그램의 실행 시간을 단축 시켜준다.
(이러한 절차를 '알고리즘'이라고 한다.)
3. 프로그램 구현과 유지보수를 쉽게 하기 위해
효율적은 구조는 프로그램 개발을 쉽게 만들어주고 이해하기 쉬워 협업자들로 하여금 분석하는 시간을 줄여준다.
Thread는 Process 내에서 실행되는 여러 흐름 단위를 말한다. 각각의 Thread는 독립적으로 작동하며, 여러 개의 스레드가 동시에 실행될 수 있다. 이를 통해 프로그램의 응답성을 향상시키고, 프로세서를 보다 효율적으로 사용할 수 있다.
예를 들어, 한 프로그램에서 파일을 다운로드하는 작업과 사용자 입력을 처리하는 작업이 동시에 진행되어야 한다면, 이 두 작업을 각각의 Thread에서 처리할 수 있다.
🌳 < 자바에서 Thread 사용하기 >
Java에서는 "Thread" 클래스를 직접 상속받거나, 'Runnalbe' 인터페이스를 구현하는 방식으로 스레드를 생성할 수 있다.
class MyRunnable implements Runnable {
public void run() {
// 스레드에서 실행할 작업을 구현
}
}
public class Main {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable());
t.start(); // 스레드 실행
}
}
🤔 < 동기화란? >
동기화는 여러 스레드가 동시에 공유 데이터에 접근하는 것을 제어하는 메커니즘이다. 이는 데이터 일관성을 유지하고, 동시 수정으로 인한 오류를 방지하는데 필요하다.
예를 들어, 두 개의 스레드가 동시에 같은 계좌에서 돈을 출금하는 상황을 생각해보면. 이 때 동기화가 되지 않으면, 두 Thread가 동시에 잔액을 확인하고 동시에 돈을 출금하게 되어, 실제 잔액보다 더 많은 돈이 출금될 수 있다.
🌳 < 자바에서 async 사용하기 >
자바에서는 synchronized 키워드를 사용하여 동기화를 구현할 수 있다. synchronized 키워드는 메소드 또는 블록에 적용할 수 있다. synchronized가 적용된 메소드 또는 블록은 한 번에 하나의 스레드만 접근할 수 있다.
class SharedResource {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
update employee t1
set salary = salary * 1.1
where empno = ( select t2.manager
from department t2
where t2.deptno = t1.deptno);
update employee t1
set salary = salary * 1.1
where empno in ( select t2.manager
from department t2);
commit;
select * from employee;
4. 사원 중 같은 성(姓)을 가진 사람이 몇 명이나 되는지 성별 인원수를 구하시오.
select substr(t1.name,1,1) "성", count(*) "인원수"
from employee t1
group by substr(t1.name,1,1);
5. ‘영업팀’ 부서에서 일하는 사원의 이름, 연락처, 주소를 보이시오. (단 연락처 없으면 ‘연락처 없음’ , 연락처 끝4자리 중 앞2자리는 별표 * 로 표시하시오. 예) 010-111-**78 )
select t2.name "이름",
nvl2(phoneno,substr(phoneno,1,8) || '**' || substr(phoneno,11,2),'연락처없음') "연락처",
t2.address "주소"
from department t1, employee t2
where t1.deptno = t2.deptno
and t1.deptname = '영업팀';
6. ‘홍길동7’ 팀장(manager) 부서에서 일하는 팀원의 수를 보이시오.
select count(*) "팀원 수"
from employee
where deptno = ( select t2.deptno
from department t1, employee t2
where t1.deptno = t2.deptno
and t2.name = '홍길동7' )
and name <> '홍길동7';
7. 프로젝트에 참여하지 않은 사원의 이름을 보이시오.
left outer join 사용
select t1.name
from employee t1, works t2
where t1.empno = t2.empno(+)
and t2.projno is null;
상관쿼리 사용
select t1.name
from employee t1
where not exists ( select *
from works t2
where t2.empno = t1.empno );
not in 사용
select name
from employee
where empno not in ( select distinct empno
from works );
차집합 사용
select name
from employee
where empno in ( select empno
from employee
minus
select distinct empno
from works );
8. 급여 상위 TOP 3를 순위와 함께 보이시오.
select rownum, t1.*
from ( select *
from employee
order by salary desc ) t1
where rownum <=3;
9. 사원들이 일한 시간 수를 부서별, 사원 이름별 오름차순으로 보이시오.
select t1.deptname "부서명", t2.name "이름", nvl(sum(t3.hoursworked),0) "일한 시간"
from department t1, employee t2, works t3
where t2.deptno = t1.deptno(+)
and t2.empno = t3.empno(+)
group by t1.deptname, t2.name
order by t1.deptname, t2.name;
10. 2명 이상의 사원이 참여한 프로젝트의 번호, 프로젝트명, 사원의 수를 보이시오.
select t2.projno "프로젝트 번호",
t2.projname "프로젝트명",
count(*) "사원수"
from works t1, project t2
where t1.projno = t2.projno
group by t2.projno, t2.projname
having count(*) >= 2;
11. 3명 이상의 사원이 있는 부서의 사원 이름을 보이시오.
select t3.deptname "부서명", t4.name "이름"
from department t3, employee t4
where t3.deptno = t4.deptno
and t3.deptno in ( select t1.deptno
from department t1, employee t2
where t1.deptno = t2.deptno
group by t1.deptno
having count(*) >= 3 );
12. 프로젝트에 참여시간이 가장 많은 사원과 적은 사원의 이름을 보이시오.
select t2.empno "사번", t1.name "이름", sum(t2.hoursworked) "시간"
from employee t1 , works t2
where t1.empno = t2.empno
group by t2.empno, t1.name
having sum(t2.hoursworked) in ( (select max(sum(hoursworked))
from works
group by empno),
(select min(sum(hoursworked))
from works
group by empno));
select empno "사번",
(select name
from employee
where empno = works.empno) "이름",
sum(hoursworked) "시간"
from works
group by empno
having sum(hoursworked) in ( (select max(sum(hoursworked))
from works
group by empno),
(select min(sum(hoursworked))
from works
group by empno));
합집합 사용
select t2.empno, t1.name, sum(t2.hoursworked)
from employee t1 , works t2
where t1.empno = t2.empno
group by t2.empno, t1.name
having sum(t2.hoursworked) in ( select max(sum(hoursworked))
from works
group by empno )
union
select t2.empno, t1.name, sum(t2.hoursworked)
from employee t1 , works t2
where t1.empno = t2.empno
group by t2.empno, t1.name
having sum(t2.hoursworked) in ( select min(sum(hoursworked))
from works
group by empno );
13. 사원이 참여한 프로젝트에 대해 사원명, 프로젝트명, 참여시간을 보이는 뷰를 작성하시오.
create or replace view vw_proj (name, projectname, hours)
as
select t2.name, t3.projname, sum(t1.hoursworked)
from works t1, employee t2, project t3
where t1.empno = t2.empno
and t1.projno = t3.projno
group by t2.name, t3.projname
order by t2.name, t3.projname;
select name "이름",projectname "프로젝트명",hours "참여시간"
from vw_proj;
14. EXISTS 연산자로 ‘빅데이터 구축’ 프로젝트에 참여하는 사원의 이름을 보이시오.
select t1.name "이름"
from employee t1
where exists ( select *
from project t2, works t3
where t2.projno = t3.projno
and t3.empno = t1.empno
and t2.projname = '빅데이터구축' );
15. employee 테이블의 name,phoneno 열을 대상으로 인덱스를 생성하시오. (단.인덱스명은 ix_employee2)
create index ix_employee2 on employee(name,phoneno);
select *
from user_indexes
where table_name = 'EMPLOYEE'
and index_name = 'IX_EMPLOYEE2';
select publisher "출판사",
count(bookid) "도서건수",
max(price) "최고가격",
min(price) "최저가격",
sum(price) "도서가격의 합"
from book
group by publisher
order by publisher;
9. 도서가격이 가장 비싼 도서와 가장 싼도서의 가격차이를 보이시오.
select max(price) "가장 비싼 도서 가격",
min(price) "가장 싼 도서가격",
max(price)-min(price) "차이"
from book;
10. 고객 중 구매건수가 2회 이상인 고객번호, 구매건수를 구매건수 순으로 보이시오.
select custid "고객번호", count(orderid) "구매건수"
from orders
group by custid
having count(orderid) >= 2
order by count(orderid);
11. 2020년 7월 4일~7월 7일 사이에 주문 받은 도서를 제외한 도서의 주문번호를 보이시오.
select orderid "도서의 주문번호"
from orders
where not (orderdate between '20200704' and '20200707');
select orderid "도서의 주문번호"
from orders
where not (orderdate >= '20200704' and orderdate <= '20200707');
select orderid "도서의 주문번호"
from orders
where orderdate < '20200704' or orderdate > '20200707';
12. 주문일자별 매출액을 매출액 내림차순으로 보이시오.
select orderdate "주문일자", sum(saleprice) "매출액"
from orders
group by orderdate
order by sum(saleprice) desc;
13. 2020년 7월2일 이후에 주문일별 매출액이 20000원을 초과하는 주문일자를 최근 일자순 보이시오.
select orderdate "주문일자", sum(saleprice) "매출액"
from orders
where orderdate > '20200702'
group by orderdate
having sum(saleprice) > 20000
order by orderdate desc;
14. 출판사별 도서건수가 2건 이상인 출판사를 보이시오.
select publisher "출판사", count(bookid) "도서건수"
from book
group by publisher
having count(bookid) >= 2;
15. 새로운 도서가 아래 입고 되었다. 추가된 결과를 보이시오.
-- 제목 : 데이터베이스, 출판사 : 한빛, 가격 : 30000
insert into book values(11,'데이터베이스','한빛',30000);
commit;
select * from book;
16. 출판사 “대한미디어”가 “대한출판사‘로 이름이 바뀌었다. 변경된 결과를 보이시오.
update book
set publisher = '대한출판사'
where publisher = '대한미디어';
commit;
select * from book;
17. 굿스포츠 출판사 도서의 가격을 10% 인상하였다. 변경된 결과를 보이시오.
update book
set price = price * 1.1 -- price + price * 0.1
where publisher = '굿스포츠';
commit;
select * from book;
18. 추신수 고객의 주소가 “대한민국 울산”으로 변경되었다. 변경된 결과를 보이시오.
update customer
set address = '대한민국 울산'
where name = '추신수';
commit;
select * from customer;
19. 전화번호가 없는 고객을 삭제하고 반영된 결과를 보이시오.
delete from customer
where phone is null;
commit;
select * from customer;
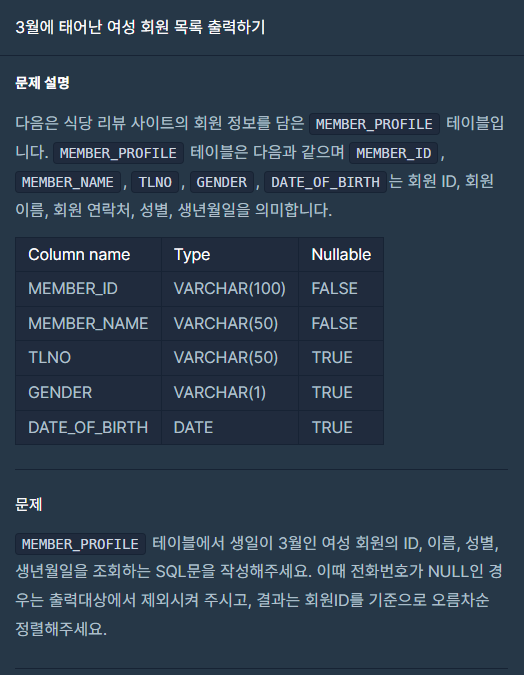
다음은 고객의 정보를 담은MEMBER_PROFILE테이블과 식당의 리뷰 정보를 담은REST_REVIEW테이블입니다.MEMBER_PROFILE테이블은 다음과 같으며MEMBER_ID,MEMBER_NAME,TLNO,GENDER,DATE_OF_BIRTH는 회원 ID, 회원 이름, 회원 연락처, 성별, 생년월일을 의미합니다.
Column name
Type
Nullable
MEMBER_ID
VARCHAR(100)
FALSE
MEMBER_NAME
VARCHAR(50)
FALSE
TLNO
VARCHAR(50)
TRUE
GENDER
VARCHAR(1)
TRUE
DATE_OF_BIRTH
DATE
TRUE
REST_REVIEW테이블은 다음과 같으며REVIEW_ID,REST_ID,MEMBER_ID,REVIEW_SCORE,REVIEW_TEXT,REVIEW_DATE는 각각 리뷰 ID, 식당 ID, 회원 ID, 점수, 리뷰 텍스트, 리뷰 작성일을 의미합니다.
Column name
Type
Nullable
REVIEW_ID
VARCHAR(10)
FALSE
REST_ID
VARCHAR(10)
TRUE
MEMBER_ID
VARCHAR(100)
TRUE
REVIEW_SCORE
NUMBER
TRUE
REVIEW_TEXT
VARCHAR(1000)
TRUE
REVIEW_DATE
DATE
TRUE
문제
MEMBER_PROFILE와REST_REVIEW테이블에서 리뷰를 가장 많이 작성한 회원의 리뷰들을 조회하는 SQL문을 작성해주세요. 회원 이름, 리뷰 텍스트, 리뷰 작성일이 출력되도록 작성해주시고, 결과는 리뷰 작성일을 기준으로 오름차순, 리뷰 작성일이 같다면 리뷰 텍스트를 기준으로 오름차순 정렬해주세요.
SELECT A.MEMBER_NAME, B.REVIEW_TEXT, TO_CHAR(B.REVIEW_DATE,'YYYY-MM-DD') AS REVIEW_DATE
FROM MEMBER_PROFILE A, REST_REVIEW B
WHERE A.MEMBER_ID = B.MEMBER_ID
AND A.MEMBER_ID IN (
SELECT MEMBER_ID FROM
(
-- 유저 ID 및 유저별 리뷰 수를 구하는 쿼리
SELECT MEMBER_ID, COUNT(*) AS CNT FROM REST_REVIEW
GROUP BY MEMBER_ID)
WHERE CNT =
(
-- 최대 리뷰 수 구하는 쿼리
SELECT MAX(COUNT(*)) AS MAXCNT FROM REST_REVIEW
GROUP BY MEMBER_ID)
)
ORDER BY B.REVIEW_DATE, B.REVIEW_TEXT;
OR
With을 써서, 이름을 직접 부여도 가능하다.
WITH review_counts AS (
SELECT MEMBER_ID, COUNT(*) AS review_count
FROM REST_REVIEW
GROUP BY MEMBER_ID
),
max_count AS (
SELECT MAX(review_count) AS max_review_count
FROM review_counts
),
top_reviewers AS (
SELECT MEMBER_ID
FROM review_counts
WHERE review_count = (SELECT max_review_count FROM max_count)
)
SELECT A.MEMBER_NAME, B.REVIEW_TEXT, TO_CHAR(B.REVIEW_DATE,'YYYY-MM-DD') AS REVIEW_DATE
FROM MEMBER_PROFILE A, REST_REVIEW B
WHERE A.MEMBER_ID = B.MEMBER_ID
AND A.MEMBER_ID IN (SELECT MEMBER_ID FROM top_reviewers)
ORDER BY B.REVIEW_DATE, B.REVIEW_TEXT;
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d")
FROM MEMBER_PROFILE
WHERE DATE_FORMAT(DATE_OF_BIRTH, '%m') = '03' AND GENDER = 'W' AND TLNO IS NOT NULL
ORDER BY MEMBER_ID
;
[oracle]
SELECT
MEMBER_ID,
MEMBER_NAME,
GENDER,
TO_CHAR(DATE_OF_BIRTH, 'YYYY-MM-DD') AS DATE_OF_BIRTH
FROM
MEMBER_PROFILE
WHERE
TLNO is not NULL AND
TO_CHAR(DATE_OF_BIRTH, 'MM') = 3 AND
GENDER = 'W'
ORDER BY
MEMBER_ID ASC
[모든 레코드 조회하기]
문제 설명
ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON_INTAKE는 각각 동물의 아이디, 생물 종, 보호 시작일, 보호 시작 시 상태, 이름, 성별 및 중성화 여부를 나타냅니다.
NAME
TYPE
NULLABLE
ANIMAL_ID
VARCHAR(N)
FALSE
ANIMAL_TYPE
VARCHAR(N)
FALSE
DATETIME
DATETIME
FALSE
INTAKE_CONDITION
VARCHAR(N)
FALSE
NAME
VARCHAR(N)
TRUE
동물 보호소에 들어온 모든 동물의 정보를 ANIMAL_ID순으로 조회하는 SQL문을 작성해주세요. SQL을 실행하면 다음과 같이 출력되어야 합니다.
ANIAL_ID
ANIMAL_TYPE
DATETIME
INTAKE_CONDITION
NAME
SEX_UPON_INTAKE
A349996
Cat
2018-01-22 14:32:00
Normal
Sugar
Neutered Male
A350276
Cat
2017-08-13 13:50:00
Normal
Jewel
Spayed Female
A350375
Cat
2017-03-06 15:01:00
Normal
Meo
Neutered Male
A352555
Dog
2014-08-08 04:20:00
Normal
Harley
Spayed Female
[oracle],[mysql]
SELECT *
FROM ANIMAL_INS
WHERE ANIMAL_ID like '%A%'
ORDER BY ANIMAL_ID
SELECT *
FROM ANIMAL_INS
ORDER BY ANIMAL_INS.ANIMAL_ID;
혹은 ORDER BY 절에서 ANIMAL_INS를 제외해도 된다.
[오프라인/온라인 판매 데이터 통합하기]
다음은 어느 의류 쇼핑몰의 온라인 상품 판매 정보를 담은 ONLINE_SALE 테이블과 오프라인 상품 판매 정보를 담은 OFFLINE_SALE 테이블 입니다. ONLINE_SALE 테이블은 아래와 같은 구조로 되어있으며 ONLINE_SALE_ID, USER_ID, PRODUCT_ID, SALES_AMOUNT, SALES_DATE는 각각 온라인 상품 판매 ID, 회원 ID, 상품 ID, 판매량, 판매일을 나타냅니다.
Column nameTypeNullable
ONLINE_SALE_ID
INTEGER
FALSE
USER_ID
INTEGER
FALSE
PRODUCT_ID
INTEGER
FALSE
SALES_AMOUNT
INTEGER
FALSE
SALES_DATE
DATE
FALSE
동일한 날짜, 회원 ID, 상품 ID 조합에 대해서는 하나의 판매 데이터만 존재합니다.
OFFLINE_SALE 테이블은 아래와 같은 구조로 되어있며 OFFLINE_SALE_ID, PRODUCT_ID, SALES_AMOUNT, SALES_DATE는 각각 오프라인 상품 판매 ID, 상품 ID, 판매량, 판매일을 나타냅니다.
Column nameTypeNullable
OFFLINE_SALE_ID
INTEGER
FALSE
PRODUCT_ID
INTEGER
FALSE
SALES_AMOUNT
INTEGER
FALSE
SALES_DATE
DATE
FALSE
동일한 날짜, 상품 ID 조합에 대해서는 하나의 판매 데이터만 존재합니다.
문제
ONLINE_SALE 테이블과 OFFLINE_SALE 테이블에서 2022년 3월의 오프라인/온라인 상품 판매 데이터의 판매 날짜, 상품ID, 유저ID, 판매량을 출력하는 SQL문을 작성해주세요. OFFLINE_SALE 테이블의 판매 데이터의 USER_ID 값은 NULL 로 표시해주세요. 결과는 판매일을 기준으로 오름차순 정렬해주시고 판매일이 같다면 상품 ID를 기준으로 오름차순, 상품ID까지 같다면 유저 ID를 기준으로 오름차순 정렬해주세요.
각 테이블의 2022년 3월의 판매 데이터를 합쳐서, 정렬한 결과는 다음과 같아야 합니다.
SALES_DATEPRODUCT_IDUSER_IDSALES_AMOUNT
2022-03-01
1
NULL
2
2022-03-01
3
NULL
3
2022-03-01
4
NULL
1
2022-03-01
4
4
1
2022-03-02
2
2
2
2022-03-02
3
6
3
2022-03-03
2
NULL
1
2022-03-03
5
5
1
[ORACLE]
SELECT TO_CHAR(SALES_DATE,'YYYY-MM-DD') AS SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT
FROM (
SELECT SALES_DATE, PRODUCT_ID, USER_ID AS USER_ID, SALES_AMOUNT
FROM ONLINE_SALE
WHERE SALES_DATE BETWEEN TO_DATE('2022-03-01','YYYY-MM-DD') AND TO_DATE('2022-03-31','YYYY-MM-DD')
UNION ALL
SELECT SALES_DATE, PRODUCT_ID, NULL AS USER_ID, SALES_AMOUNT
FROM OFFLINE_SALE
WHERE SALES_DATE BETWEEN TO_DATE('2022-03-01','YYYY-MM-DD') AND TO_DATE('2022-03-31','YYYY-MM-DD')
)
ORDER BY TO_DATE(SALES_DATE,'YYYY-MM-DD') , PRODUCT_ID, USER_ID
[MYSQL]
SELECT
DATE_FORMAT(SALES_DATE,"%Y-%m-%d") AS SALES_DATE
,PRODUCT_ID
,USER_ID
,SALES_AMOUNT
FROM ONLINE_SALE
WHERE
SALES_DATE >='2022-03-01 00:00:00' AND SALES_DATE <'2022-04-01 00:00:00'
UNION ALL
SELECT
DATE_FORMAT(SALES_DATE,"%Y-%m-%d") AS SALES_DATE
,PRODUCT_ID
, null AS user_id
, SALES_AMOUNT
FROM OFFLINE_SALE
WHERE
SALES_DATE >='2022-03-01 00:00:00' AND SALES_DATE <'2022-04-01 00:00:00'
ORDER BY 1,2,3
[인기있는 아이스크림]
FIRST_HALF 테이블은 아이스크림 가게의 상반기 주문 정보를 담은 테이블입니다.FIRST_HALF 테이블 구조는 다음과 같으며, SHIPMENT_ID, FLAVOR, TOTAL_ORDER는 각각 아이스크림 공장에서 아이스크림 가게까지의 출하 번호, 아이스크림 맛, 상반기 아이스크림 총주문량을 나타냅니다.
SHIPMENT_ID
INT(N)
FALSE
FLAVOR
VARCHAR(N)
FALSE
TOTAL_ORDER
INT(N)
FALSE
문제
상반기에 판매된 아이스크림의 맛을 총주문량을 기준으로 내림차순 정렬하고 총주문량이 같다면 출하 번호를 기준으로 오름차순 정렬하여 조회하는 SQL 문을 작성해주세요.
[ORACLE],[MYSQL]
SELECT FLAVOR
FROM FIRST_HALF
ORDER BY TOTAL_ORDER DESC, SHIPMENT_ID ASC;
[아픈 동물 찾기]
NAME
TYPE
NULL
ANIMAL_ID
VARCHAR(N)
FALSE
ANIMAL_TYPE
VARCHAR(N)
FALSE
DATETIME
DATETIME
FALSE
INTAKE_CONDITION
VARCHAR(N)
FALSE
NAME
VARCHAR(N)
TRUE
SEX_UPON_INTAKE
VARCHAR(N)
FALSE
동물 보호소에 들어온 동물 중 아픈 동물의 아이디와 이름을 조회하는 SQL 문을 작성해주세요. 이때 결과는 아이디 순으로 조회해주세요.
HTTP(HyperText Transfer Protocol)는 웹상에서 데이터를 주고 받는 방식을 정의하는 프로토콜이다. HTTP의 기본적인 특징을 이해하면 웹의 동작 방식을 더욱 잘 이해할 수 있다. HTTP의 핵심 특징 3가지인 클라이언트-서버구조, 무상태 프로토콜(Stateless), 그리고 단순하면서도 확장 가능한 특징에 대해 자세히 알아보겠다.
< 1. HTTP는 클라이언트-서버 구조로 되어 있다.>
HTTP는 클라이언트-서버 구조를 가지고 있다. 클라이언트는 HTTP 메세지를 통해 서버에게 요청을 보내고, 그 요청에 대한 응답을 기다린다. 응답이 오면, 클라이언트는 해당 응답을 통해 웹페이지를 렌더링한다. 이때, 클라이언트는 사용자 인터페이스와 사용자 경험에 집중 하고, 데이터와 비즈니스 로직 처리는 서버에게 맡긴다. 이런 분업 체계 덕분에 클라이언트와 서버는 각각 독립적으로 발전할 수 있다.
예를 들어, 서버 트래픽이 발전하더라도 클라이언트를 수정할 필요는 없다. 백엔드에서 트래픽 관리에 집중하면 되는 것이다.
< 2. HTTP는 무상태 프로토콜(Stateless)상태를 지향한다.>
HTTP는 클라이언트의 상태를 보존하지 않는다. 이 말은 클라이언트의 이전 요청을 기억하지 않는다는 뜻이다.
이해를 돕기 위해 간단한 예들이 있다.
예를 들어, 노트북을 사려는 고객과 점원 간의 대화가 있다고 가정해보자. 고객이 노트북 가격을 묻고, 점원이 가격을 말한 후, 고객이 두 대를 사겠다고 하면, 점원은 전에 언급된 노트북 가격을 기억하고 두 대의 가격을 계산할 수 있다. 이 상황이 Stateful 상황이다.
반면에, Stateful 상황에서 점원이 중간에 바뀌면 문제가 생긴다.
이러한 것에 대한 단점이 있으며,
Stateless Protocol은 이는 HTTP가 클라이언트의 상태를 기억하지 않는다는 뜻이다.
즉, 중간에 점원(서버)가 바뀌어도 대화(요청)이 이어갈 수 있다는 것이다.
이러한 방식은 대규모 시스템에서 확장성을 크게 향상 시킨다.
<Stateless의 실무 한계>
예를 들어, 사용자가 로그인한 상태를 유지하는 것은 "무상태 프로토콜"로는 어렵다. 이러한 한계를 극복하기 위해, '쿠키'나 '세션'과 같은 기술이 개발되었다. 이런 기술들은 클라이언트와 서버 사이에 추가적인 정보를 주고 받을수 있도록 하여, 상태를 일정하게 유지할 수 있게 한다.
<비연결성>
비연결성이란 말 그대로 서버와 클라이언트 사이의 연결을 계속 유지하지 않는다는 것을 의미한다. 서버는 클라이언트의 요청에 응답하고나면 연결을 끊어버린다. 이렇게 함으로써 서버의 자원을 최적화 하고, 많은 클라이언트의 요청을 동시에 처리할 수 있게 된다.
예를 들어, 웹 브라우저에서 한 번에 여러 개의 요청을 보내는 경우, HTTP는 각 요청마다 독립적인 연결을 생성한다. 그래서 한 요청이 처리되고 나면 해당 연결은 끊어지고, 다음 요청이 올 때까지 연결은 유지되지 않는다. 이렇게 비연결성을 가진 덕분에, 서버는 동시에 많은 수의 클라이언트의 요청을 처리할 수 있게 된다.
그러나, 단점도 존재 한다.
첫째로, 매 요청마다 새로운 연결을 만들어야 하기 때문에 이로 인해 추가적인 시간이 소모된다. 그리고 이로 인해 웹 페이지를 로딩하는 시간이 늘어나 사용자의 경험이 저하될 수 있다.
둘째로, 웹 페이지를 로딩하는데 필요한 많은 자원들(예:이미지,Javascript,CSS등)을 요청해야 한다. 이는 많은 네트워크 트래픽을 증가시키며, 비효율적인 작업이 될 수 있다.hello 단어 하나만 쳐도 무수히 많은 것이 다운로드 되고 있다.
그래서 생긴 해결책: 지속 연결(Persistent Connection)
이런 단점들을 해결하기 위해 HTTP는 '지속 연결(Persistent Connection)'이라는 개념을 도입했다. 이는 한 번의 연결로 여러 요청과 응답을 처리할 수 있도록 하는 방법이다. 이후의 HTTP 버전인 HTTP/2,HTTP/3에서는 이 개념을 더욱 발전시켜, 여러 요청을 동시에 처리할 수 있는 능력을 더욱 강화시켰다.
요약하면, HTTP의 비연결성은 서버의 자원을 효율적으로 관리하는데 큰 도움을 주지만, 그로 인한 사용자 경험의 저하와 같은 단점을 가지고 있다. 이를 해결하기 위해 '지속 연결'이라는 개념이 도입되어, 현재의 웹 통신에서는 이를 통해 더욱 효율적이고 빠른 통신이 가능해졌다.